|
|
在《前端知识链路笔记 - 前后端通讯篇之HTTP协议基础介绍》中我们介绍了 HTTP 通讯协议系列相关基础理论知识,这篇文章将专注于拓展介绍下 HTTP 协议中通讯字段,以五大实际生产开发中所涉及到的案例(HTTP 跨域、HTTP 条件请求、HTTP 缓存、HTTP 通讯压缩、HTTP 身份验证)作为展开,详细讲解 HTTP 协议中常见的通讯字段(共 28 个)当然,实际上 HTTP 协议包含的通讯字段远远不止这 28 个(实际共有 118 个),大家也可以直接参考 MDN 上有关 HTTP 协议通讯字段的相关资料 进行查阅学习。
相关知识点快速导航目录
先放个锚点在这,之后等写完其他知识链路笔记将会实时编辑更新 ( •̀ ω •́ )✧
- 前端知识链路笔记 - 前后端通讯篇之 HTTP 协议基础介绍
- 前端知识链路笔记 - 前后端通讯篇之前后端跨域通讯及解决方案(未写完)
- 前端知识链路笔记 - 前后端通讯篇之 HTTP 条件请求(未写完)
- 前端知识链路笔记 - 前后端通讯篇之 HTTP 缓存机制(未写完)
- 前端知识链路笔记 - 前后端通讯篇之 前后端通讯缓存(未写完)
- 前端知识链路笔记 - 前后端通讯篇之 HTTP 通讯压缩(未写完)
- 前端知识链路笔记 - 前后端通讯篇之 身份验证(未写完)
1、案例一:HTTP 跨域
要说到 HTTP 最老生常谈的问题,那莫过于 HTTP 跨域问题了,在介绍有关 HTTP 跨域相关的 HTTP 通讯字段之前,就先简单介绍下 HTTP 跨域是什么吧。
HTTP 跨域的基本概念
HTTP 跨域又称 跨源资源共享(CORS;Cross-Origin Resource Sharing) ,其为一种基于 HTTP 响应报文头中设置一系列特定 HTTP 通讯字段来使得浏览器判定接收到 HTTP 请求报文的服务器中是否标识了这个 HTTP 请求报文所隶属的 origin(域、协议及端口)(即该服务器 CORS 白名单中是否存在发起 HTTP 请求所隶属站点的 origin 信息),从而保证安全的 HTTP 跨域请求通讯解决方案。
跨源资源共享 (CORS)(或通俗地译为跨域资源共享)是一种基于 HTTP 头的机制,该机制通过允许服务器标示除了它自己以外的其它 origin(域,协议和端口),使得浏览器允许这些 origin 访问加载自己的资源。跨源资源共享还通过一种机制来检查服务器是否会允许要发送的真实请求,该机制通过浏览器发起一个到服务器托管的跨源资源的"预检"请求。在预检中,浏览器发送的头中标示有 HTTP 方法和真实请求中会用到的头。 —— MDN > Web 开发技术 > 跨源资源共享(CORS) 当然,解决 跨域通讯 的方式远不止 HTTP 跨域(CORS)这一种方案,在此就不做详细叙述,有兴趣的话可以参考《前端知识链路笔记 - 前后端通讯篇之前后端跨域通讯及解决方案(未写完)》。
HTTP 跨域所关联的 HTTP 通讯字段
1、Access-Control-Allow-Origin
Access-Control-Allow-Origin 隶属于 HTTP 响应报文 头部通讯字段,其表明该响应报文所附带的数据资源是否允许给指定的 origin(域、协议及端口) 共享使用。
Access-Control-Allow-Origin 的取值有且仅有三种形式:
# 表示允许任意 origin 共享使用该响应报文资源
Access-Control-Allow-Origin: *
# 表示允许某一特定 origin 共享使用该响应报文资源
Access-Control-Allow-Origin: <origin>
# 表示不允许任何外部网络的 origin 共享使用该响应报文资源,
# 但允许隶属于本服务器局域网络的以 data:xxx【即 Data URI(Uniform Resource Identifier) 释义:统一资源标识协议】
# 或以 file:xxx【即 File Protocol 释义:本地文件传输协议】的 origin 共享使用该响应报文资源
Access-Control-Allow-Origin: null注意:
HTTP 规则中 Access-Control-Allow-Origin 仅允许同时设置唯一一个 origin 作为报文字段,因此网上流传的一些 Access-Control-Allow-Origin 多 origin 写法是错误的,以下写法均为错误写法:
# 错误示范1:使用 , 分隔多个 origin
Access-Control-Allow-Origin: www.baidu.com, www.taobao.com
# 解析:
# 该设置意为允许名为 www.baidu.com, www.taobao.com 的 origin 共享该响应报文资源, 但显然这并不符合 origin 的格式
# 不可能存在名为 www.baidu.com, www.taobao.com 这样的 origin, 因此这样设置实际效果与不设置该字段无异
# 错误示范2:同时设置多个 Access-Control-Allow-Origin 并且赋予不同值
Access-Control-Allow-Origin: www.baidu.com
Access-Control-Allow-Origin: www.taobao.com
# 解析:
# 由于浏览器的安全防护机制(即防止 HTTP 响应报文被中间劫持, 又称 HTTP 劫持攻击),
# 当浏览器解析出该报文存在多个 Access-Control-Allow-Origin 时, 会判定该 HTTP 报文隶属于不安全的报文
# 这时该报文中所有 Access-Control-Allow-Origin 设置均将不生效
# 错误示范3:使用正则匹配多个不同的 origin
Access-Control-Allow-Origin: www.*.com
# 解析:
# 该设置字面意思为允许任何符合带有 www. 前缀和 .com 后缀的 origin 匹配,
# 但非常可惜的是浏览器并不允许这么设置, 浏览器会将其解析为仅允许名为 www.*.com 的 origin 共享该响应报文资源
# 从效果上来看, 浏览器针对 Access-Control-Allow-Origin 的解析是完全匹配的模式(也就是直接 c++ 的 == 判定)但是在实际生产中,允许多个指定的 origin 可共享使用资源的场景非常常见,那么该如何实现这个需求呢?
其实解决方案也很简单,目前主流的通用解决方案是先行判定 HTTP 请求报文所隶属的 origin 是否存在于该服务器的 CORS 白名单列表当中,若存在则将 Access-Control-Allow-Origin 的值设置为 HTTP 请求报文所隶属的 origin,同时设置 Vary 头字段为 origin 表明该服务器返回的 HTTP 响应报文的 Access-Control-Allow-Origin 为可变值,若不存在则不设置 Access-Control-Allow-Origin。
兼容性:
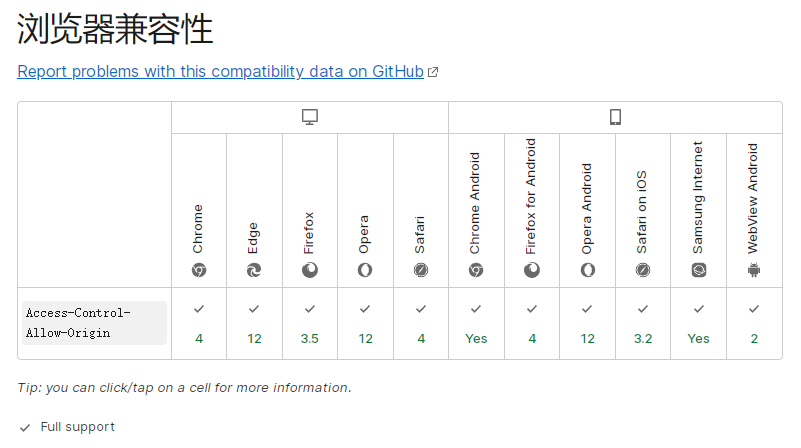
图片转自 参考资料[1] 的 Access-Control-Allow-Origin 词条
2、Access-Control-Allow-Methods
Access-Control-Allow-Methods 通讯字段专用于 HTTP 跨域中 非简单请求【详细可见 《前端知识链路笔记 - 前后端通讯篇之前后端跨域通讯及解决方案(未写完)》 或 MDN > Web 开发技术 > HTTP > 跨源资源共享(CORS)】中的 preflight request(即预检请求) 所对应的服务器 HTTP 响应报文头。
其用于表示接受到 HTTP 预检请求的服务器允许客户端在后续的 正式 HTTP 请求报文 中可使用指定的请求方法来获取到该类资源,例如:
# 允许客户端使用 POST、OPTIONS 方法针对该非简单请求所隶属的资源进行访问
Access-Control-Allow-Methods: POST, OPTIONSAccess-Control-Allow-Methods的取值有且仅有两种形式:
# 表示允许任意方法访问该类资源
Access-Control-Allow-Methods: *
# 表示允许某些特定方法访问该类资源, 多种不同的方法使用 , 进行分隔
Access-Control-Allow-Methods: <method>, <method>, ...兼容性:
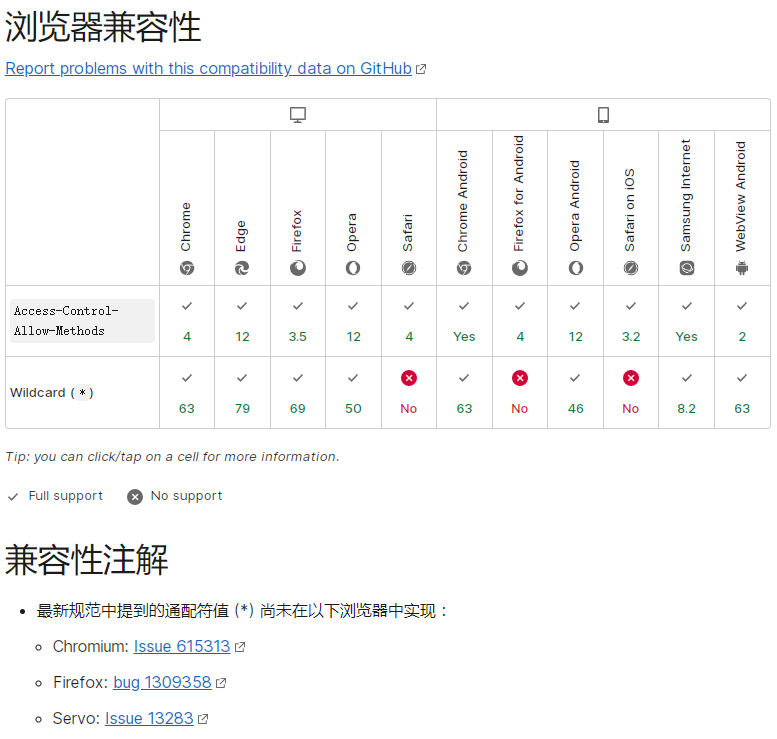
图片转自 参考资料[1] 的 Access-Control-Allow-Methods 词条
3、Access-Control-Allow-Headers
Access-Control-Allow-Headers 通讯字段专用于 HTTP 跨域中 非简单请求 中的 preflight request(即预检请求) 所对应的服务器 HTTP 响应报文头。
其用于表示接受到 HTTP 预检请求的服务器允许客户端在后续的 正式 HTTP 请求报文 中 的 Access-Control-Request-Headers 字段中所允许出现的头部信息字段(即服务器可解析的 HTTP 请求头部字段),例如:
# 表明 正式 HTTP 请求报文中除 simple headers 相关字段外还允许包含 X-Custom-Header, Upgrade-Insecure-Requests
Access-Control-Allow-Headers: X-Custom-Header, Upgrade-Insecure-Requests注意:
注意以下这些特定的首部是一直允许的:Accept, Accept-Language, Content-Language, Content-Type(但只在其值属于 MIME 类型application/x-www-form-urlencoded, multipart/form-data或text/plain中的一种时)。这些被称作 simple headers,你无需特意声明它们。 —— MDN > Web 开发技术 > HTTP > HTTP Headers > Access-Control-Allow-Headers
Access-Control-Allow-Headers 的取值有且仅有两种形式:
# 表明 正式 HTTP 请求报文中允许包含任意字段
Access-Control-Allow-Headers: *
# 表明 正式 HTTP 请求报文中除 simple headers 相关字段外还允许包含某些特定的字段, 多个字段使用 , 分隔
Access-Control-Allow-Headers: <header-name>[, <header-name>]*兼容性:
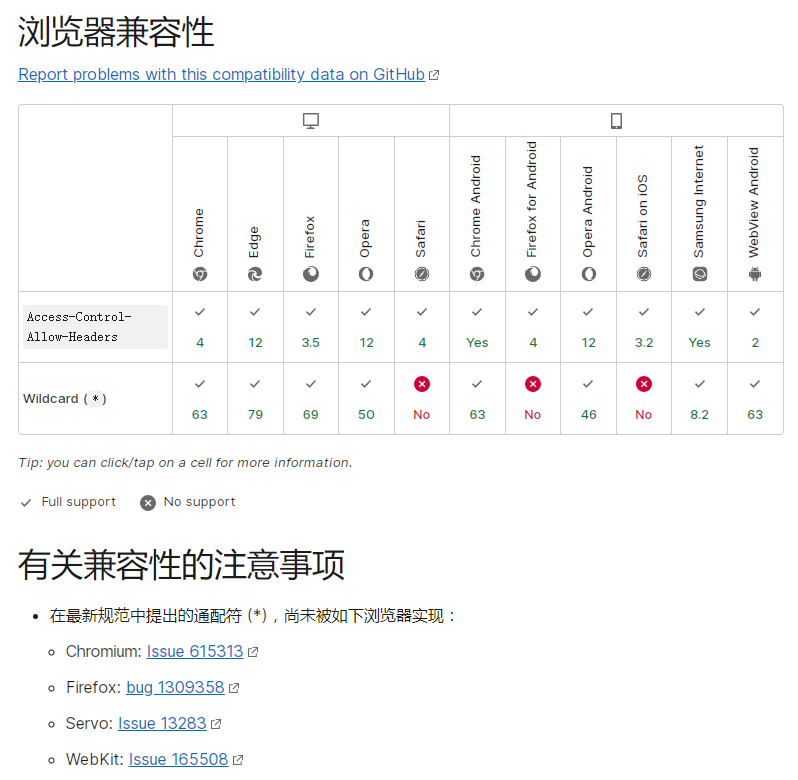
图片转自 参考资料[1] 的 Access-Control-Allow-Headers 词条
4、Access-Control-Allow-Credentials
Access-Control-Allow-Credentials 通讯字段存在于响应报文头中,其用于当 HTTP 请求报文要求其请求的服务器在响应该请求报文时提供相应的 Credentials(即 Request.credentials 的值为include),由此通讯字段告知浏览器是否可以将对请求的响应暴露给前端 JavaScript 代码。
即当一段 HTTP 请求的 credentials 模式设置(Request.credentials)为include时,浏览器仅会在 HTTP 响应报文头信息包含且Access-Control-Allow-Credentials的值为 true 的情况下将 HTTP 响应报文信息资源 暴露给前端的 JavaScript 代码。
Credentials 可以是 cookies、authorization headers 或 TLS client certificates。 但当该 HTTP 请求报文作为 HTTP 跨域中 非简单请求 中的 preflight request(即预检请求) 时,响应该 预检请求 的响应报文中的 Access-Control-Allow-Credentials通讯字段表示接下来的 正式请求 是否拥有使用 credentials 的权限。
注意:
1、对于 HTTP 跨域当中形如 GET 这类的 简单请求 来说并没有预检请求,所以若一个对资源的请求需要携带 credentials 进行身份认证,如果响应该请求的响应报文当中并没有 Credentials 跟随带有 Access-Control-Allow-Credentials字段的 HTTP 响应报文头信息返回,则该响应报文所携带的资源就会被浏览器忽视,浏览器将不会加载该响应资源。
MDN 相关文档资料(中文):
当作为对预检请求的响应的一部分时,这能表示是否真正的请求可以使用 credentials。注意简单的GET请求没有预检,所以若一个对资源的请求带了 credentials,如果这个响应头没有随资源返回,响应就会被浏览器忽视,不会返回到 web 内容。 —— MDN > Web 开发技术 > HTTP > HTTP Headers > Access-Control-Allow-Credentials MDN 相关文档资料(英文):
When used as part of a response to a preflight request, this indicates whether or not the actual request can be made using credentials. Note that simple GET requests are not preflighted. So, if a request is made for a resource with credentials, and if this header is not returned with the resource, the response is ignored by the browser and not returned to the web content.
2、Access-Control-Allow-Credentials通讯字段需要与XMLHttpRequest.withCredentials 或 Fetch API 的 Request() 构造函数中的credentials选项结合使用。Credentials 必须在前后端都被配置(即Access-Control-Allow-Credentialsheader 和 XHR 或 Fetch request 中都要配置)才能使携带 Credentials 的 CORS 请求成功。
Access-Control-Allow-Credentials 的取值有且仅有一种形式:
# 表该响应报文允许携带 Credentials 传输至发起请求的客户端并供给给其使用
Access-Control-Allow-Credentials: true注意:不存在形如 Access-Control-Allow-Credentials 值为 false 的写法,如果不希望将 Credentials 提供给请求所隶属的客户端,则无需在响应报文中设置 Access-Control-Allow-Credentials 通讯字段。
兼容性:

图片转自 参考资料[1] 的 Access-Control-Allow-Credentials 词条
5、Access-Control-Expose-Headers
Access-Control-Expose-Headers 通讯字段用于表示包含该通讯字段的 HTTP 响应报文中除 simple response headers(简单响应首部) 外还有那些头部通讯字段可供接收该 HTTP 响应报文的客户端所解析调用。
Access-Control-Expose-Headers 的取值有且仅有两种形式:
# 表示容许暴露给接收该响应报文的客户端的处于该响应报文当中所含有的任意通讯字段
Access-Control-Expose-Headers: *
# header-name 表示容许暴露给接收该响应报文的客户端的处于该响应报文当中所含有的其他通讯字段, 例如:X-Kuma-Revision 等
# 多个字段使用 , 分隔
Access-Control-Expose-Headers: <header-name>, <header-name>, ...兼容性:

图片转自 参考资料[1] 的 Access-Control-Expose-Headers 词条
6、Access-Control-Request-Method
Access-Control-Request-Method 通讯字段仅用于 预检请求 的 HTTP 请求报文当中,用于告知接收该请求的服务器在后续的 正式请求 当中将会采用哪种 Method(HTTP 方法)。这是因为所有 预检请求 所使用的 Method 总会是OPTIONS,这与 正式请求 所使用的方法不一样,因此需要该字段来特别说明,方便判定请求所访问的服务器资源是否容许 正式请求 所采用的 HTTP 方法。
Access-Control-Request-Method 的取值有且仅有一种形式:
# 这用于告知服务器在接下来的 正式请求 当中, 客户端将会采用 method 来请求该资源
Access-Control-Request-Method: <method>注意:对于一个 HTTP 请求,其 method 都是唯一特定的,因此不存在一次请求 method 值可能为多个不同的值的情况,因此 Access-Control-Request-Method 不存在多个 method 值。
兼容性:
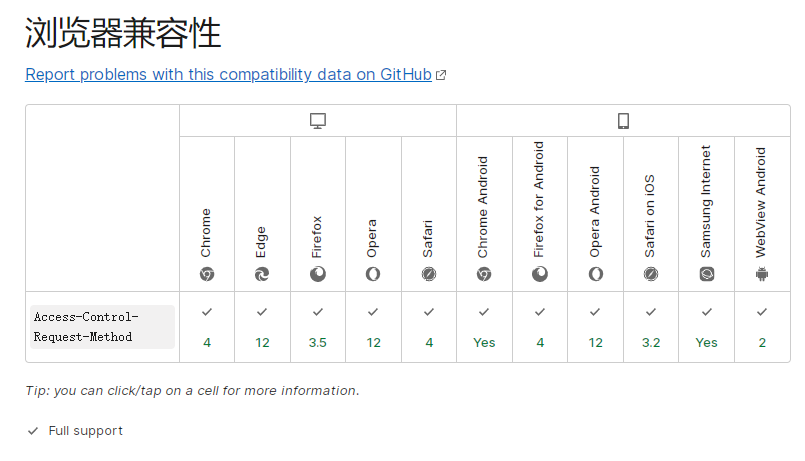
图片转自 参考资料[1] 的 Access-Control-Request-Method 词条
7、Access-Control-Request-Headers
Access-Control-Request-Headers 通讯字段仅用于 预检请求 的 HTTP 请求报文当中,用于告知接收该请求的服务器在后续的 正式请求 当中将会包含哪些 HTTP 通讯字段。这是因为所有 预检请求 所包含的通讯字段与 正式请求 不尽相同,因此需要该字段来特别说明,方便判定请求所访问的服务器资源是否兼容 正式请求 中所包含的 HTTP 通讯字段。
Access-Control-Request-Headers 的取值有且仅有一种形式:
# 这用于告知服务器在接下来的 正式请求 当中, 客户端发送的 HTTP 请求报文将会包含那些 HTTP 通讯字段
# 多个不同的 HTTP 通讯字段采用 , 进行分隔
Access-Control-Request-Headers: <header-name>, <header-name>, ...注意:对于一个 HTTP 请求,其所包含的所有 HTTP 通讯字段都是预先可知的,因此不存在一次请求中所包含的 HTTP 通讯字段存在变值的情况。
兼容性:
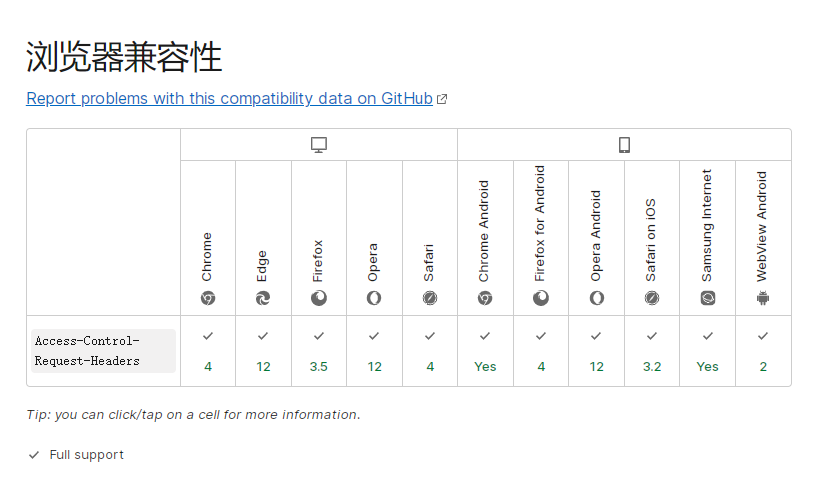
图片转自 参考资料[1] 的 Access-Control-Request-Headers 词条
8、Access-Control-Max-Age
Access-Control-Max-Age 通讯字段仅存在于响应 预检请求 的 HTTP 响应报文当中,表示响应的 预检请求 的返回结果(即 Access-Control-Allow-Methods 和 Access-Control-Allow-Headers 提供的信息) 可以被容许缓存多久,其该取值为 s(秒),该时间以发送该响应报文的服务器的时间序列为准。
Access-Control-Max-Age的取值有且仅有一种形式:
# 表示响应 预检请求 的返回结果最多被容许缓存 delta-seconds 秒
Access-Control-Max-Age: <delta-seconds><delta-seconds>:返回结果可以被缓存的最长时间(秒)。 在 Firefox 中,上限是 24 小时 (即 86400 秒)。 在 Chromium v76 之前, 上限是 10 分钟(即 600 秒)。 从 Chromium v76 开始,上限是 2 小时(即 7200 秒)。 Chromium 同时规定了一个默认值 5 秒。 如果值为 -1,表示禁用缓存,则每次请求前都需要使用 OPTIONS 预检请求。 兼容性:

图片转自 参考资料[1] 的 Access-Control-Max-Age 词条
2、案例二:HTTP 条件请求
HTTP 通讯又一大重点案例就是 HTTP 的条件请求了,不过 HTTP 条件请求这个概念可能并没有在日常工作中接触到,但实际上,我们在工作当中经常能够听到的 HTTP 的资源协商缓存 其实就是 HTTP 条件请求的一个应用点,那么接下来,我们就介绍从 HTTP 资源协商缓存讲起,逐步介绍整个 HTTP 条件请求的基础概念【关于HTTP 资源协商缓存 与 HTTP 条件请求的讲解可见《前端知识链路笔记 - 前后端通讯篇之 HTTP 条件请求(未写完)》】,并以此为依据,介绍与 HTTP 条件请求相关的 HTTP 通讯字段。
HTTP 通讯协商缓存 与 HTTP 条件请求的基本概念
HTTP 通讯协商缓存又称 HTTP 协商通讯(HTTP 协商缓存),其运用场景为:对于一份数据资源,由于一系列的原因(例如数据过大,通讯成本高等原因),需要在客户端存储一份该数据资源的副本,但是该资源又可能存在更新行为,需要在该资源更新后,客户端再次请求该资源时将存储在客户端的副本文件与服务端的原始文件相同步,从而实现既能够尽量减小资源的通讯成本开销,亦能够保证资源的更新。
而 HTTP 通讯协商缓存 其底层依据的就是 HTTP 条件式请求(即 HTTP 条件请求) 这一概念,对于 HTTP 条件请求来说,其通过 HTTP 请求报文头所设置的一系列 条件通讯字段 来使得 HTTP 报文的响应结果因这些 条件通讯字段 及 请求所采用的通讯方法 不同而改变。
- 对于安全的 HTTP(safe)方法来说,例如 GET,通常用来获取文件,条件请求可以被用来限定仅在满足条件的情况下返回文件。这样可以节省带宽。
- 对于非安全 HTTP(unsafe)方法来说,例如 PUT 方法,通常用来上传文件,条件请求可以被用来限定仅在满足文件的初始版本与服务器上的版本相同的条件下才会将其上传。
在 HTTP 协议中有一个“条件式请求”的概念,在这类请求中,请求的结果,甚至请求成功的状态,都会随着验证器与受影响资源的比较结果的变化而变化。这类请求可以用来验证缓存的有效性,省去不必要的控制手段,以及验证文件的完整性,例如在断点续传的场景下或者在上传或者修改服务器端的文件的时候避免更新丢失问题。 —— MDN > Web 开发技术 > HTTP > HTTP 条件请求 拓展:条件通讯字段(又称条件首部) 指的是形如 If-xxx 这样的通讯字段,其包含:
1、If-Match
如果远端资源的实体标签与在ETag这个首部中列出的值相同的话,表示条件匹配成功。默认地,除非实体标签带有 &#39;W/&#39; 前缀,否者它将会执行强验证。
2、If-Modified-Since
如果远端资源的 Last-Modified 首部标识的日期比在该首部中列出的值要更晚,表示条件匹配成功。
3、If-None-Match
如果远端资源的实体标签与在ETag这个首部中列出的值都不相同的话,表示条件匹配成功。默认地,除非实体标签带有 &#39;W/&#39; 前缀,否者它将会执行强验证。
4、If-Range
与If-Match或If-Unmodified-Since相似,但是只能含有一个实体标签或者日期值。如果匹配失败,则条件请求宣告失败,此时将不会返回 206 Partial Content 响应码,而是返回 200 OK 响应码,以及完整的资源。
5、If-Unmodified-Since
如果远端资源的 Last-Modified 首部标识的日期比在该首部中列出的值要更早或相同,表示条件匹配成功。
HTTP 条件请求的应用场景
详见 MDN > Web 开发技术 > HTTP > HTTP 条件请求/应用场景
HTTP 通讯协商缓存 及 HTTP 条件请求 所关联的 HTTP 通讯字段
1、Last-Modified
Last-Modified 通讯字段用于 HTTP 响应报文 中,其值表示该资源隶属的源头服务器【因为可能存在多级 CDN 缓存,因此响应该请求的服务器未必是该资源的源头服务器】所认定的该资源的最后修改日期及时间。 Last-Modified通常被用作一个验证器来判断接收到的或者存储的资源是否彼此一致。但是由于 Last-Modified的判定精确度比 ETag 要低,因此 Last-Modified 的判定优先级要低于ETag。
只有在响应包含有If-Modified-Since 或 If-Unmodified-Since 通讯字段的 HTTP 请求时,对应该请求的 HTTP 响应报文才会包含 Last-Modified 字段。
Last-Modified 的取值有且仅有一种形式:
# 表示该资源是在 GMT(国际标准时间)的 day month year hour:minute:second 进行了最后一次修改, 这个时间的日期标签为 day-name
Last-Modified: <day-name>, <day> <month> <year> <hour>:<minute>:<second> GMT
# 示例:表示该资源是在 GMT(国际标准时间)的 21 Oct 2015 07:28:00 进行了最后一次修改, 这天是 Wed(星期三)
Last-Modified: Wed, 21 Oct 2015 07:28:00 GMT说明:
- <day-name>:&#34;Mon&#34;, &#34;Tue&#34;, &#34;Wed&#34;, &#34;Thu&#34;, &#34;Fri&#34;, &#34;Sat&#34; 或 &#34;Sun&#34; 之一(区分大小写)。
- <day>:两位数字表示的天数,例如&#34;04&#34; or &#34;23&#34;。
- <month>:&#34;Jan&#34;, &#34;Feb&#34;, &#34;Mar&#34;, &#34;Apr&#34;, &#34;May&#34;, &#34;Jun&#34;, &#34;Jul&#34;, &#34;Aug&#34;, &#34;Sep&#34;, &#34;Oct&#34;, &#34;Nov&#34;, &#34;Dec&#34; 之一(严格区分大小写)。
- <year>:4 位数字表示的年份,例如 &#34;1990&#34; 或者&#34;2016&#34;。
- <hour>:两位数字表示的小时数,例如 &#34;09&#34; 或者 &#34;23&#34;。
- <minute>:两位数字表示的分钟数,例如&#34;04&#34; 或者 &#34;59&#34;。
- <second>:两位数字表示的秒数,例如 &#34;04&#34; 或者 &#34;59&#34;。
- GMT:国际标准时间。HTTP 中的时间均用国际标准时间表示,从来不使用当地时间。
兼容性:
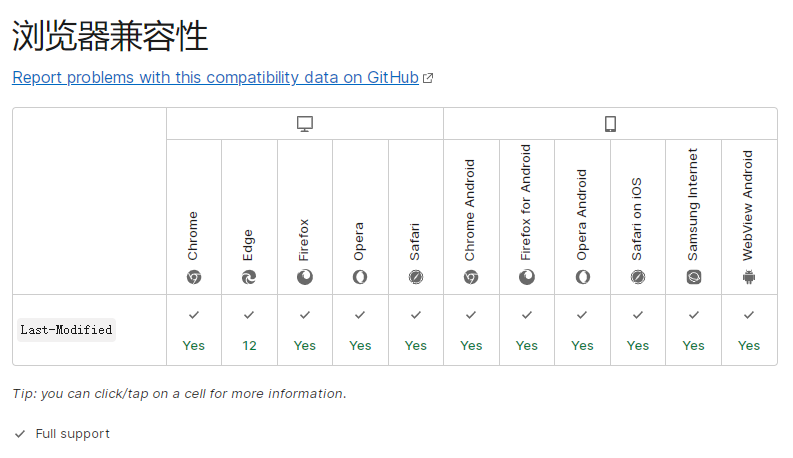
图片转自 参考资料[1] 的 Last-Modified 词条
2、Etag
ETag 通讯字段用于 HTTP 响应报文 中,其为一串特定的标记值,用作于记录 某一特定版本的资源。这可以让缓存更高效,并节省带宽,因为如果对应资源不存在改变时,服务器并不需要发送包含资源数据的响应报文。而如果资源发生了变化,使用 ETag 则有助于防止资源同时更新导致的相互覆盖的情况(又称资源的“空中碰撞”, 其解决方案可见 MDN > Web 开发技术 > HTTP > HTTP Headers > ETag/避免“空中碰撞”)。
Etags 的意义类似于资源的唯一性表示,通过比较 Etags 就能快速确定此资源是否变化。如果所对应的资源发生实质性的更改(指资源所对应的二进制字节序列存在修改),则资源的源头服务器必须要为该资源生成新的 Etag 值,并广播更新到逐级 CDN 资源服务器当中。
Etag 的取值有且仅有两种形式:
# 表示该报文对应的资源的 Etag 为 大小写敏感的弱验证器, 其 Etag 值为 <etag_value>, 包裹 <etag_value> 的 &#34;&#34; 符号是必须的
ETag: W/&#34;<etag_value>&#34;
# 表示该报文对应的资源的 Etag 为 <etag_value>, 包裹 <etag_value> 的 &#34;&#34; 符号是必须的
ETag: &#34;<etag_value>&#34;说明:
1、W/可选
&#39;W/&#39;(大小写敏感) 表示使用 弱验证器。 弱验证器很容易生成,但不利于比较。 强验证器是比较的理想选择,但很难有效地生成。 相同资源的两个弱Etag值可能语义等同,但不是每个字节都相同。
2、&#34;<etag_value>&#34;
实体标签唯一地表示所请求的资源。 它们是位于双引号之间的 ASCII 字符串(如“675af34563dc-tr34”)。 没有明确指定生成 ETag 值的方法。 通常,使用内容的散列,最后修改时间戳的哈希值,或简单地使用版本号。 例如,MDN 使用 wiki 内容的十六进制数字的哈希值。
兼容性:

图片转自 参考资料[1] 的 Etag 词条
3、If-Match
If-Match 通讯字段用于 HTTP 请求报文 中,在请求方法为 GET 和 HEAD 的情况下,服务器仅在请求的资源满足 If-Match 列出的 ETag 值时才会返回资源。而对于 PUT 或其他非安全方法来说,只有在满足 HTTP 条件请求(即资源符合该请求的所有 HTTP 条件通讯字段) 的情况下才可以将资源上传,其对应的两个使用场景如下:
- 对于 GET 和 HEAD 方法,搭配 Range 首部使用,可以用来保证新请求的范围与之前请求的范围是对同一份资源的请求。如果 ETag 无法匹配,那么服务器需要返回 416 Range Not Satisfiable 响应。
- 对于其他方法来说,尤其是 PUT, If-Match 首部可以用来避免 更新丢失问题。它可以用来检测用户想要上传的不会覆盖获取原始资源之后做出的更新。如果 HTTP 条件请求 不满足,那么需要返回 412 Precondition Failed 响应。
注意:
对于If-Match 来说,其默认采取的 Etag 比较算法是 强比较算法,即只有在每一个字节都相同的情况下,才可以认为两个文件是相同的。此外可以主动在 ETag 前面添加W/前缀表示可以采用相对宽松的算法。
If-Match 的取值有且仅有两种形式:
# 表示该资源的 Etag 应该为 If-Match 给定的 <etag_value> 中的任意一个, 多个 <etag_value> 应以 , 进行分隔
If-Match: <etag_value>, <etag_value>, …
# 表示该资源的 Etag 可以是任意值
If-Match: *说明:
- <etag_value>:唯一地表示一份资源的实体标签。标签是由 ASCII 字符组成的字符串,用双引号括起来(如 &#34;675af34563dc-tr34&#34;)。前面可以加上 W/ 前缀表示应该采用弱比较算法。
- *:星号是一个特殊值,可以指代任意资源。
兼容性:

图片转自 参考资料[1] 的 If-Match 词条
4、If-Modified-Since
If-Modified-Since 通讯字段用于 HTTP 请求报文 中,服务器只在所请求的资源在给定的日期时间之后对内容进行过修改(即 Last-Modified 改变)的情况下才会将资源返回,状态码为 200 OK。如果请求的资源从那时起未经修改,那么服务器将返回一个不带有消息主体的 304 Not Modified 响应,而在该响应报文头中的 Last-Modified 字段表示该资源最后一次修改的时间。 不同于 If-Unmodified-Since, If-Modified-Since只可以用在 GET 或 HEAD 请求中。
注意:
1、由于 If-Modified-Since 的比较方式为比较资源的 Last-Modified,这与比较 Etag 不同,即便该资源的二进制字节序列完全相同,但只要最后修改时间被重写,则判定为该资源被改变。
2、当 If-Modified-Since 与 If-None-Match 一同出现时,If-Modified-Since将被服务器忽略掉,除非该服务器不支持If-None-Match 字段。
If-Modified-Since 的取值有且仅有一种形式:
# 表示该资源的 Last-Modified 应该为 If-Match 给定的内容, 其指令值与 Last-Modified 字段指令值完全一致
If-Modified-Since: <day-name>, <day> <month> <year> <hour>:<minute>:<second> GMT兼容性:

图片转自 参考资料[1] 的 If-Modified-Since 词条
5、If-None-Match
If-None-Match 通讯字段用于 HTTP 请求报文 中,对于 GET 和 HEAD 请求方法来说,当且仅当服务器上没有任何资源的 ETag 属性值与这个首部中列出的相匹配的时候,服务器端才会返回所请求的资源,响应码为 200 OK。对于其他方法来说,当且仅当最终确认没有已存在的资源的 ETag 属性值与这个首部中所列出的相匹配的时候,才会对请求进行相应的处理。
对于 GET 和 HEAD 方法来说,当验证失败的时候,服务器端必须返回响应码 304 Not Modified。对于能够引发服务器状态改变的方法,则返回 412 Precondition Failed。需要注意的是,服务器端在生成状态码为 304 的响应报文的时候,该报文必然包含以下同时会存在于对应的 200 响应报文中的字段:Cache-Control、Content-Location、Date、ETag、Expires 和 Vary 。
对于 If-None-Match 来说其默认采取的 ETag 比较算法采用的是 弱比较算法,即两个文件除了每个字节都相同外,内容一致也可以认为是相同的。例如,如果两个页面仅仅在页脚的生成时间有所不同,就可以认为二者是相同的。
当与 If-Modified-Since 一同使用的时候,If-None-Match 优先级更高(仅在服务器支持 If-None-Match 字段时)。
对于 If-None-Match来说,其有两个主要的运用场景:
- 采用 GET 或 HEAD 方法,来更新拥有特定的 ETag 属性值的缓存。
- 采用其他方法,尤其是 PUT,将 If-None-Match 的值设置为 * ,用来生成事先并不知道是否存在的文件,可以确保先前并没有进行过类似的上传操作,防止之前操作数据的丢失。这个问题属于 更新丢失问题 的一种。
If-None-Match 的取值有且仅有两种形式:
# 表示该资源的 Etah 应该为 If-None-Match 给定的 <etag_value> 值, 多个 <etag_value> 用 , 分隔
If-None-Match: <etag_value>, <etag_value>, …
# 表示该资源的 Etag 可为任意值
If-None-Match: *说明:
- <etag_value>:唯一地表示所请求资源的实体标签。形式是采用双引号括起来的由 ASCII 字符串(如&#34;675af34563dc-tr34&#34;),有可能包含一个 W/ 前缀,来提示应该采用弱比较算法(这个是画蛇添足,因为 If-None-Match 用且仅用这一算法)。
- *:星号是一个特殊值,可以代表任意资源。它只用在进行资源上传时,通常是采用 PUT 方法,来检测拥有相同识别 ID 的资源是否已经上传过了。
兼容性:

图片转自 参考资料[1] 的 If-None-Match 词条
6、If-Range
If-Range 通讯字段用于 HTTP 请求报文 中,其用来使得 Range 通讯字段在 If-Range 字段值得到满足时,Range 字段才会生效,这时,服务器将回复包含 206 Partial Content 部分内容状态码的 HTTP 响应报文,该响应 HTTP 报文包含 Range 头字段所请求的相应部分资源;倘若 If-Range字段值中的条件没有得到满足,服务器则将会返回 200 OK 状态码,并返回完整的请求资源。
字段值中既可以用 Last-Modified 时间值用作验证,也可以用ETag标记作为验证,但不能将两者同时使用。
If-Range 头字段通常用于断点续传的下载过程中,用来自从上次中断后,确保下载的资源没有发生改变。
对于 If-Range 来说,当其值为 Etag 值时,其默认采取的 Etag 比较算法是 强比较算法,即只有在每一个字节都相同的情况下,才可以认为两个文件是相同的。此外可以主动在 ETag 前面添加 W/ 前缀表示可以采用相对宽松的算法。
If-Range 的取值有且仅有两种形式:
# 表示请求的资源所对应的 Last-Modified 需要与 If-Range 一致, 该请求的 Range 字段才视为生效
If-Range: <day-name>, <day> <month> <year> <hour>:<minute>:<second> GMT
# 表示请求的资源所对应的 Etag 需要与 If-Range 一致, 该请求的 Range 字段才视为生效
If-Range: <etag>兼容性:

图片转自 参考资料[1] 的 If-Range 词条
7、If-Unmodified-Since
If-Unmodified-Since通讯字段用于 HTTP 请求报文 中,其表示只有当资源在指定的时间之后没有进行过修改的情况下(即对比 Last-Modified),服务器才会返回请求的资源,或是接受 POST 或其他 非safe(non-safe) 方法的请求。如果所请求的资源在指定的时间之后发生了修改,那么会返回 412 Precondition Failed 错误。
If-Unmodified-Since常见的运用场景有两种:
- 与 non-safe 方法如 POST 搭配使用,可以用来 优化并发控制,例如在某些 wiki 应用中的做法:假如在原始副本获取之后,服务器上所存储的文档已经被修改,那么对其作出的编辑会被拒绝提交。
- 与含有 If-Range 消息头的范围请求搭配使用,用来确保新的请求片段来自于未经修改的文档。
If-Unmodified-Since 的取值有且仅有一种形式:
If-Unmodified-Since: <day-name>, <day> <month> <year> <hour>:<minute>:<second> GMT兼容性:

图片转自 参考资料[1] 的 If-Unmodified-Since 词条
3、案例三:HTTP 缓存
提到 HTTP 通讯,不得不提的就是 HTTP 缓存了,要想做好 HTTP 性能优化,那围绕 HTTP 缓存的相关工作必不可少,此外,对于 HTTP 缓存来说,Cookie 等浏览器缓存机制的使用将贯彻其中,针对于 Cookie 等浏览器缓存相关的讲解可见《前端知识链路笔记 - 前后端通讯篇之 前后端通讯缓存(未写完)》。那么在介绍有关 HTTP 缓存相关的 HTTP 通讯字段之前,就先简单介绍下 HTTP 缓存的基础理论吧。
HTTP 缓存 的基本概念
HTTP 缓存 用于存储与请求关联的 HTTP 响应资源,并将存储的响应资源复用于后续的同类资源请求当中,这样保证了 HTTP 请求资源的可复用性,其表现为以下优点:
首先,由于不需要将请求传递到源服务器,因此客户端和缓存所在的数据地址越近,响应速度就越快(响应速度:客户端本地缓存 > 各级 CDN 资源缓存服务器 > 资源源头服务器)。最典型的例子是浏览器本身的缓存机制为浏览器请求存储缓存资源【详细可见《前端知识链路笔记 - 前后端通讯篇之 前后端通讯缓存(未写完)》】。
此外,当响应资源可复用时,资源源头服务器(源服务器)并不需要处理请求——因为它不需要解析和路由请求、根据 cookie 恢复会话、查询数据库以获取结果或渲染模板引擎,只需要将其交由客户端本身或各级 CDN 资源缓存服务器即可,这大大减少了源服务器上的负载。
对于 HTTP 缓存来说,根据 HTTP 规范 RTC9111 - HTTP Caching,其可以分为 私有缓存 和 共享缓存 两种类型,
关于 HTTP 缓存 相关的详细介绍可见《前端知识链路笔记 - 前后端通讯篇之 HTTP 缓存机制(未写完)》或 MDN > Web 开发技术 > HTTP > HTTP 缓存。
HTTP 缓存 所关联的 HTTP 通讯字段
HTTP 缓存常与 HTTP 条件请求相关,除了会涉及到 案例二 HTTP 条件请求外的字段外,还会涉及到以下 HTTP 通讯字段:
1、Cache-Control
Cache-Control 为通用型 HTTP 通讯字段,其即可被包含于 HTTP 请求报文当中,也可以被包含于 HTTP 响应报文当中,HTTP 通讯通过Cache-Control值记录的指定指令来实现 HTTP 通讯资源的缓存机制。
值得注意的是,Cache-Control所记录的缓存指令是 单向生效 的,这意味着在 HTTP 请求中设置的Cache-Control指令,不一定被包含在响应该 HTTP 请求的 HTTP 响应报文当中。
Cache-Control 的取值形式繁多,依据其存在于 HTTP 报文类型可分为以下两大类:
①、Cache-Control 在 HTTP 请求报文 当中的取值形式:
# 表示该缓存存储允许存在的最大周期,单位为秒,超过 <seconds> 的缓存被认为过期
# 与 Expires 相反,该时间基准是相对于请求发送的时间,而并非服务器响应的时间
Cache-Control: max-age=<seconds>
# 表明客户端愿意接收一个已经过期的资源,默认容许返回的过期资源的过期时间为无限久。
# 同时可以给定一个可选的秒数,表示即便该响应允许返回一个过期资源,该资源过期时间也不能已经超过给定的 <seconds>
Cache-Control: max-stale[=<seconds>]
# 表示客户端希望获取一个包含在指定的秒数内且保持其最新状态的资源的响应
Cache-Control: min-fresh=<seconds>
# 表示在使用缓存的副本资源之前,强制要求把包含该资源相关信息的 HTTP 请求发送给原始服务器进行失效验证 (协商缓存验证)
Cache-control: no-cache
# 表示不应存储有关客户端请求或服务器响应的任何内容,即不使用任何缓存
Cache-control: no-store
# 表示不得对资源进行转换或转变(即 Content-Encoding、Content-Range、Content-Type 等 HTTP 通讯字段不能由代理修改)
# 例如,非透明代理 或 例如 Google&#39;s Light Mode 可能对图像格式进行转换,以便节省缓存空间或者减少缓慢链路上的流量,设置了 no-transform 指令时则不允许这样做
Cache-control: no-transform
# 表明客户端只允许接受已缓存的响应,并且不需要向原始服务器检查该资源是否有更新的拷贝
Cache-control: only-if-cached②、Cache-Control 在 HTTP 响应报文 当中的取值形式
# 表示一旦当前响应服务器判定资源过期(比如已经超过max-age),在成功向资源源头服务器完成资源过期验证之前,该缓存不能用于该资源响应的后续请求当中
Cache-control: must-revalidate
# 表示在使用缓存的副本资源之前,强制要求把包含该资源相关信息的 HTTP 请求发送给原始服务器进行失效验证 (协商缓存验证)
# 响应报文会取该值的情况存在于响应当前请求的服务器并非资源的原始服务器,即缓存当前资源的缓存服务器(通常为 CDN 服务器或代理服务器)
Cache-control: no-cache
# 表示不应存储有关客户端请求或服务器响应的任何内容,即不使用任何缓存
Cache-control: no-store
# 表示不得对资源进行转换或转变(即 Content-Encoding、Content-Range、Content-Type 等 HTTP 通讯字段不能由代理修改)
# 例如,非透明代理 或 例如 Google&#39;s Light Mode 可能对图像格式进行转换,以便节省缓存空间或者减少缓慢链路上的流量,设置了 no-transform 指令时则不允许这样做
Cache-control: no-transform
# 表明响应可以被任何对象(包括:发送请求的客户端,代理服务器,等等)缓存,即使是通常不可缓存的内容。
# 例如:1.该响应没有包含 max-age 指令或 Expires 通讯字段; 2. 该响应对应的请求方法是 POST
Cache-control: public
# 表明响应只能被单个用户缓存,不能作为共享缓存(即代理服务器不能缓存该响应资源)。
# 而私有缓存则可以缓存响应内容,比如:对应用户的本地浏览器。
Cache-control: private
# 与 Cache-control: must-revalidate 作用相同,但它仅适用于共享缓存(例如代理缓存),对于私有缓存则不生效。
Cache-control: proxy-revalidate
# 表示该缓存存储允许存在的最大周期,单位为秒,超过 <seconds> 的缓存被认为过期
# 当该字段被包含于 HTTP 响应报文当中时, 其时间基准为当前响应的服务器中的时间(未必等同于资源原始服务器的时间)
Cache-Control: max-age=<seconds>
# 表示覆盖 max-age 或 Expires 通讯字段,但是仅适用于共享缓存 (比如各个代理的缓存),对于私有缓存则该字段不生效。
Cache-control: s-maxage=<seconds>
除此之外,Cache-Control 还有有一些实验阶段的指令值,这些指令值暂时并没有被纳入到 HTTP 正式标准当中,因此最好不要将其使用在生产环境当中,并且在使用之前请确认其在各浏览器的兼容性。
# 表示 HTTP 响应报文的正文内容不会随时间而改变。资源(如果未过期)在服务器上不发生改变,
# 因此客户端不应发送重新验证请求头(例如If-None-Match或 If-Modified-Since)来检查更新,即使用户显式地刷新页面
Cache-control: immutable
# 表示客户端愿意接受陈旧的响应(即以前曾经发送过的响应),同时在后台异步检查新的响应
# <seconds>表示客户愿意接受陈旧响应的最长时间长度
Cache-control: stale-while-revalidate=<seconds>
# 表示如果新的检查失败,则客户端愿意接受陈旧的响应(即以前曾经发送过的响应)
# <seconds>表示客户在初始到期后愿意接受陈旧响应的最长时间长度
Cache-control: stale-if-error=<seconds>
说明:
1、可缓存类指令值:
- public:表明响应可以被任何对象(包括:发送请求的客户端,代理服务器,等等)缓存,即使是通常不可缓存的内容。(例如:该响应没有max-age指令或Expires消息头或 该响应对应的请求方法是 POST )
- private:表明响应只能被单个用户缓存,不能作为共享缓存(即代理服务器不能缓存它)。私有缓存可以缓存响应内容,比如:对应用户的本地浏览器。
- no-cache:在发布缓存副本之前,强制要求缓存把请求提交给原始服务器进行验证 (协商缓存验证)。
- no-store:缓存不应存储有关客户端请求或服务器响应的任何内容,即不使用任何缓存。
2、资源过期期限指令值:
- max-age=<seconds>:设置缓存存储的最大周期,超过这个时间缓存被认为过期 (单位秒)。与Expires相反,时间是相对于请求的时间。
- s-maxage=<seconds>:覆盖max-age或者Expires头,但是仅适用于共享缓存 (比如各个代理),私有缓存会忽略它。
- max-stale[=<seconds>]:表明客户端愿意接收一个已经过期的资源。可以设置一个可选的秒数,表示响应不能已经过时超过该给定的时间。
- min-fresh=<seconds>:表示客户端希望获取一个能在指定的秒数内保持其最新状态的响应。
- stale-while-revalidate=<seconds>: 该指令为实验性指令,目前未被纳入 HTTP 正式标准当中,表明客户端愿意接受陈旧的响应,同时在后台异步检查新的响应。秒值指示客户愿意接受陈旧响应的时间长度。
- stale-if-error=<seconds>: 该指令为实验性指令,目前未被纳入 HTTP 正式标准当中,表示如果新的检查失败,则客户愿意接受陈旧的响应。秒数值表示客户在初始到期后愿意接受陈旧响应的时间。
3、资源重新验证及加载指令值:
- must-revalidate:一旦资源过期(比如已经超过max-age),在成功向原始服务器验证之前,缓存不能用该资源响应后续请求。
- proxy-revalidate:与 must-revalidate 作用相同,但它仅适用于共享缓存(例如代理),并被私有缓存忽略。
- immutable:该指令为实验性指令,目前未被纳入 HTTP 正式标准当中,表示响应正文不会随时间而改变。资源(如果未过期)在服务器上不发生改变,因此客户端不应发送重新验证请求头(例如If-None-Match或 If-Modified-Since)来检查更新,即使用户显式地刷新页面。在 Firefox 浏览器当中,immutable 只能被用在 https:// transactions. 有关更多信息,请参阅 immutable 实验说明文档。
4、其他指令值:
- no-transform:不得对资源进行转换或转变。Content-Encoding、Content-Range、Content-Type等 HTTP 头不能由代理修改。例如,非透明代理或者如 Google&#39;s Light Mode 可能对图像格式进行转换,以便节省缓存空间或者减少缓慢链路上的流量。no-transform指令不允许这样做。
- only-if-cached :表明客户端只接受已缓存的响应,并且不要向原始服务器检查是否有更新的拷贝。
使用场景
可见 MDN > Web 开发技术 > HTTP > HTTP Headers > Cache-Control/示例
兼容性:

图片转自 参考资料[1] 的 Cache-control 词条
2、Expires
Expires 通讯字段用于 HTTP 响应报文当中,其表示该响应报文所包含的资源的失效日期/时间, 即在此时间之后,响应资源视为过期。
当 Expires 的指令值被设定为一个无效的日期(比如 0,或 已经过去的日期)时,即表示该资源已经过期。
注意:如果在 HTTP 响应报文中包含 Cache-Control 通讯字段,且 Cache-Control 字段指令值设置为 &#34;max-age&#34; 或者 &#34;s-max-age&#34; 指令,那么Expires头会被忽略。
Expires 的取值有且仅有一种形式:
# 表示该资源将于 <http-date> 之后过期
Expires: <http-date>
# 示例:表示该资源将于 GMT 国际标准时间的 21 Oct 2015 07:28:00 之后过期, 那一天为星期三(Wed)
Expires: Wed, 21 Oct 2015 07:28:00 GMT说明:
<http-date>:一个 HTTP-日期 时间戳
兼容性:

图片转自 参考资料[1] 的 Expires 词条
3、Vary
Vary通讯字段用于 HTTP 响应报文,其决定了对于未来的一个 HTTP 请求的通讯字段中,应该用一个缓存的资源进行回复 (response) 还是向资源源服务器请求一个新的资源回复。Vary被服务器用来表明在 content negotiation(内容协商算法)中选择一个资源代表的时候应该包含哪些 HTTP 头部信息(HTTP headers).
在响应状态码为 304 Not Modified 的响应中,也要设置 Vary 首部,而且要与相应的 200 OK 响应设置值完全一致。
Vary 的取值有且仅有一种形式:
# 表示所有的请求都将被视为唯一并且非缓存的, 不过对于此场景来说使用 Cache-Control: no-store 来实现会更加适用
Vary: *
# 表示通过设定的一系列 <header-name> 值以用于确定缓存是否可用, 多个 <header-name> 应用 , 分隔。
Vary: <header-name>, <header-name>, ...
示例:
通过设置 Vary: User-Agent 可以实现面向不同终端的 动态服务 功能,例如:
当一份资源来说,其提供给移动端的内容是与提供给桌面端不相同的,通过设置Vary: User-Agent,可以防止移动端与桌面端之间并不会互相误用缓存资源。并且这么做还可帮助 Google 和其他搜索引擎来发现你的移动端版本的页面(即提示服务的搜索引擎命中率),同时告知他们不需要 Cloaking。
兼容性:

图片转自 参考资料[1] 的 Vary 词条
4、案例四:HTTP 通讯压缩
对于优化一个服务的性能来说,除了在 HTTP 缓存上下功夫,另外一种优化方式就是压缩 HTTP 报文所携带的资源(即 HTTP 通讯压缩)来减小 HTTP 报文的大小,减小 HTTP 报文的传输成本,在介绍有关 HTTP 通讯压缩相关的 HTTP 字段前,就先简单介绍下 HTTP 通讯压缩 的基础理论吧。
HTTP 通讯压缩 的基本概念
HTTP 通讯压缩(又称 HTTP 数据压缩)指的是针对 HTTP 报文所携带的资源(即 HTTP 报文体内容)进行压缩,这是提高 Web 站点性能的一种重要手段。对于有些资源文件来说,高达 70% 的压缩比率可以大大减低对于带宽的需求。伴随着技术的发展与进步,数据压缩算法的效率也越来越高,同时也不断有新的压缩算法被发明出来并应用在客户端与服务器端当中。
在实际应用时,web 开发者不需要亲手实现压缩机制,因为浏览器及服务器的底层逻辑都已经将其实现了,不过前提是需要确保在服务器端进行了合理的配置。当一切就绪之后,HTTP 数据压缩会在三个不同的层面发挥作用:
- 首先某些格式的文件(例如将部分非 Web 标准图片的格式转为例如 png、jpeg 或 Webp 等格式)会采用特定的优化算法进行压缩
- 其次在 HTTP 协议层面会进行通用数据加密,即数据资源会以压缩的形式进行端到端传输
- 最后数据压缩还会发生在网络连接层面,即发生在 HTTP 连接的两个节点之间
目前 HTTP 通讯压缩的技术主要分为两大类,即:
具体关于 HTTP 通讯压缩的讲解详细可见 《前端知识链路笔记 - 前后端通讯篇之 HTTP 通讯压缩(未写完)》或 MDN > Web 开发技术 > HTTP > HTTP 协议中的数据压缩。
HTTP 通讯压缩所关联的 HTTP 通讯字段
1、Content-Type
Content-Type 为通用型 HTTP 通讯字段,其即可被包含于 HTTP 请求报文当中,也可以被包含于 HTTP 响应报文当中。其用于指示 HTTP 报文所包含资源的 MIME 类型(media type)。
在响应中,Content-Type 标头告诉客户端实际返回的内容的内容类型。浏览器会在某些情况下进行 MIME 查找(又称 MIME 类型嗅探),并不一定遵循此标题的值,为了防止这种行为,可以将 X-Content-Type-Options 字段的指令值设置为 nosniff。
在 HTTP 请求中 (如 POST 或 PUT),Content-Type用于告诉服务器 HTTP 请求报文所包含资源的实际发送数据类型。
Content-Type 的取值有且仅有一种形式:
# 表示该报文所携带的资源为 <media-type> 类型, 其携带可选指令片段 charset 与 boundary, 指令片段用 ; (英文分号)分隔
# charset 用于指定该资源的字符编码标准
# boundary 则用于描述封装消息的多个部分的边界, 其对于多部分实体来说是必备指令
Content-Type: <media-type>(: charset=<character-encode>)(; boundary=<xxx>)
# 示例1:表示该报文所携带的资源为 text/html 类型资源, 其编码格式为 utf-8 编码
Content-Type: text/html; charset=utf-8
# 示例2:表示该报文所携带的资源为 form 表单类型资源, 其边界为 something
Content-Type: multipart/form-data; boundary=something说明:
- media-type:资源或数据的 MIME type 。
- charset:字符编码标准。
- boundary:对于多部分实体,boundary 是必需的,其包括来自一组字符的 1 到 70 个字符,已知通过电子邮件网关是非常健壮的,而不是以空白结尾。它用于封装消息的多个部分的边界。
兼容性:

图片转自 参考资料[1] 的 Content-Type 词条
2、X-Content-Type-Options
X-Content-Type-Options 用于 HTTP 响应报文 当中。其相当于一个提示标志,被服务器用来主动提示客户端必须要遵循在 Content-Type 首部中对 MIME 类型 的设定,而不能对其进行修改。这样就禁用了客户端的 MIME 类型嗅探 行为,换句话说,也就是意味着网站管理员必须确定自己的设置没有问题。
该消息头最初是由微软在 IE 8 浏览器中引入的,提供给网站管理员用作禁用 浏览器 MIME 类型嗅探(又称 内容嗅探)的手段(因为内容嗅探技术可能会把不可执行的 MIME 类型转变为可执行的 MIME 类型)。在此之后,其他浏览器也相继引入了这个消息头,尽管它们的 MIME 嗅探算法没有像 IE 浏览器那么有侵略性。
对于网络的安全测试人员来说,通常期望站点设置了该消息字段,因为正确设置该消息字段能够避免内容嗅探技术隐蔽的将不可执行的 MIME 类型转化为可执行的 MIME 类型资源,当然,错误的设置该字段往往会导致更为严重的结果,例如网站资源无法正常访问等异常。
注意:
X-Content-Type-Options 指令值设置为 nosniff时只能应用于 &#34;script&#34; 和 &#34;style&#34; 两种类型。事实上已经有 issues 证明,将该指令值应用于图片类型的文件会导致与现有的站点冲突的异常。
X-Content-Type-Options 的取值有且仅有一种形式:
# 表示客户端必须要遵循 HTTP 响应报文中的 Content-Type 字段对资源所隶属的 MIME 类型 设定
X-Content-Type-Options: nosniff说明:
当 X-Content-Type-Options 指令值设置为 nosniff 时,下面两种情况的请求将被阻止:
- 请求类型是&#34;style&#34; 但是 MIME 类型不是 &#34;text/css&#34;,
- 请求类型是&#34;script&#34; 但是 MIME 类型不是 JavaScript MIME 类型。
兼容性:

图片转自 参考资料[1] 的 X-Content-Type-Options 词条
3、Content-Encoding
Content-Encoding 为通用型 HTTP 通讯字段,其即可被包含于 HTTP 请求报文当中,也可以被包含于 HTTP 响应报文当中。其指令值列出了当前 HTTP 报文的 实体消息(消息荷载)所应用的所有压缩编码类型,以及压缩编码的顺序。从而使得 HTTTP 报文接受端知道需要以何种顺序及算法类型解码该实体消息才能获得原始数据荷载格式。
注意:
①、 Content-Encoding 主要用于在不丢失原媒体类型内容(即 无损压缩)的情况下压缩消息数据。
②、原始媒体/内容的类型通过 Content-Type 通讯字段给出,而 Content-Encoding 则应用于数据的表示(或称“编码形式”)。如果原始媒体本身就已经以某种方式进行编码(例如 zip 文件),则该本身已经进行的编码信息不应该被包含在 Content-Encoding 字段的指令值描述内。
③、在一般情况下服务器应对数据尽可能地进行压缩,并在适当情况下对内容进行编码。但是这种情况对于一种已经通过某种压缩过的文件编码(例如 zip 或 jpeg 等) 再进行额外的压缩并不合适,这样做反而有可能会使荷载增大(因为压缩文件需要额外包含一个解析该压缩编码的字典集数据,因此经过多种不同压缩编码格式压缩的文件可能会因为这些字典集数据而增大压缩后的载荷)。
④、服务器端并不强制要求 HTTP 报文 的 实体消息 一定需要使用何种压缩模式。究竟采用哪种压缩方式高度依赖于服务器端的设置及其所采用的模块。
Content-Encoding 的取值有且仅有一种形式:
# 表示当前 HTTP 报文的 实体消息(消息荷载)所应用的压缩编码类型及压缩编码的顺序
# <compression-code> 可以是 gzip, compress, deflate, br 中的任何一种压缩编码, 采用多种压缩编码的组合则应以 , 进行分隔
Content-Encoding: <compression-code>, <compression-code> ...说明:
- gzip:表示采用 Lempel-Ziv coding(LZ77)压缩算法,以及 32 位 CRC 校验的编码方式。这个编码方式最初由 UNIX 平台上的 gzip 程序采用。出于兼容性的考虑,HTTP/1.1 标准提议支持这种编码方式的服务器应该识别作为别名的 x-gzip 指令。
- compress:采用 Lempel-Ziv-Welch(LZW)压缩算法。这个名称来自 UNIX 系统的 compress 程序,该程序实现了前述算法。与其同名程序已经在大部分 UNIX 发行版中消失一样,这种内容编码方式已经被大部分浏览器弃用,部分因为专利问题(这项专利在 2003 年到期)。
- deflate:采用 zlib 结构(在 HTTP RFC 1950 中规定),和 deflate 压缩算法(在 HTTP RFC 1951 中规定)。
- br:表示采用 Brotli 算法的编码方式。
兼容性:
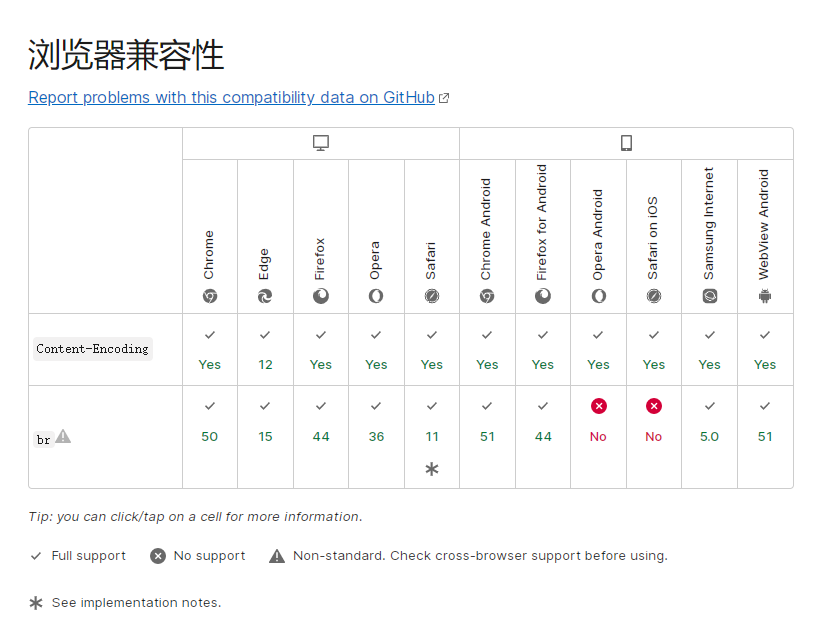
图片转自 参考资料[1] 的 Content-Encoding 词条
4、Accept-Encoding
Accept-Encoding 通讯字段用于 HTTP 请求报文 中,其指令值会将客户端能够理解的内容编码方式(通常是某种压缩算法的标志)告知服务端。通过这种内容协商的方式,服务端会选择一个客户端提议的方式,使用并在响应头 Content-Encoding 中通知客户端该选择哪一种压缩方式,这种 客户端与服务端进行内容协商 HTTP 报文所附带资源的方式也被称为 端到端压缩技术。
值得注意的是,即使客户端和服务器都支持相同的压缩算法,在 identity 指令可以被接受的情况下,服务器也可以选择对响应主体不进行压缩。导致这种情况出现的两种常见的情形是:
- 要发送的数据已经经过压缩(即传输资源本身就是 zip 这类已经被压缩过的资源文件或部分图片格式的文件),再次进行压缩不会导致被传输的数据量更小。
- 服务器超载,无法承受压缩需求导致的计算开销。通常,如果服务器使用超过其 80% 的计算能力时则不会针对 HTTP 报文所携带的资源进行压缩(微软曾建议在服务器压力过大时,不针对 HTTP 资源进行压缩以减小服务器计算开销)。
只要 Accept-Encoding: identity(即表示不需要进行任何编码)没有被明确禁止使用时(即通过设置 Accept-Encoding: identity;q=0 指令值 或是 Accept-Encoding: *;q=0 但却没有为 identity 明确指定权重值时),则服务器将禁止返回表示客户端错误的 406 Not Acceptable 响应报文。
备注: IANA 维护了一个完整的官方支持的编码方式列表。此外还有两种非标准的编码方式(bzip 和 bzip2)有时候也会用到,尽管并未在标准中出现。这两种方式实现了 UNIX 系统上的同名程序所采用的算法。注意第一种由于专利许可问题已经停止维护。
Accept-Encoding 的取值有且仅有三种形式:
# 表示客户端希望服务器以以下内容编码方式序列及每种编码格式的可选权重对 HTTP 报文所携带的资源进行压缩及解析
# <compression-code> 表示编码格式, 其值可以是标准的 gzip, compress, deflate, br 或是非标准的 bzip, bzip2
# 多个 <compression-code> 使用 , 进行分隔
# 此外每个 <compression-code> 后可以可选指令字段 q=<weight> 表示该种编码格式的随机加权权重, q=<weight> 与 <compression-code> 使用 ;(英文分号)分隔
Accept-Encoding: <compression-code>(; q=<weight>)(, <compression-code>(; q=<weight>))...
# 表示客户端希望服务器不需要针对 HTTP 报文所携带的资源进行任何形式的编码
Accept-Encoding: identity
# * 为该字段的默认值, 在此代表客户端希望服务端随便以任意一种未提供的编码方式针对 HTTP 报文所携带的资源进行编码
# 值得注意的是, * 并不代表客户端或服务端支持任意一种编码方式, 其仅仅表示选择任意一种未提供的编码格式之间不存在优先次序
Accept-Encoding: *
# 示例:用质量值(q)语法加权的多种算法:
Accept-Encoding: deflate, gzip;q=1.0, *;q=0.5说明:
- gzip:表示采用 Lempel-Ziv coding (LZ77) 压缩算法,以及 32 位 CRC 校验的编码方式。
- compress:采用 Lempel-Ziv-Welch (LZW) 压缩算法。
- deflate:采用 zlib 结构和 deflate 压缩算法。
- br:表示采用 Brotli 算法的编码方式。
- identity:用于指代自身(例如:未经过压缩和修改)。除非特别指明,这个标记始终可以被接受。
- *:匹配其他任意一个未在该请求头字段中列出的编码方式。假如该请求头字段不存在的话,这个值是默认值。它并不代表任意算法都支持,而仅仅表示选择一个未提供的编码方式之间无优先次序。
- ;q=<weight>:值代表优先顺序,用相对 质量价值 表示,又称为权重。
兼容性:

图片转自 参考资料[1] 的 Accept-Encoding 词条
5、TE
TE 通讯字段用于 HTTP 请求报文,其用于指定用户代理所希望使用的传输编码类型。(在口头交流中可以将 TE字段非正式的称为 Accept-Transfer-Encoding, 这个名称显得更直观一些)。
可以参考 Transfer-Encoding 字段来获取更多关于传输编码的细节信息。值得注意的是, 支持 HTTP/1.1 协议的接收方一定可以处理 chunked 传输编码请求,所以没有必要一定在 TE 首部指定“chunked”关键字。然而,如果客户端将要接收编码在 chunked 包体里面的&#34;trailer&#34;信息的时候,在 HTTP 请求报文中主动指定该头部将十分重要。
对于 TE 字段来说,其重要运用于 HTTP 通讯压缩的 逐跳压缩技术 场景当中。
Accept-Encoding 的取值有且仅有两种形式:
# 表示客户端在采用分块传输编码的响应中采用 <compression-code> 传输编码类型
# <compression-code> 表示编码格式, 其值可以是标准的 gzip, compress, deflate
# 多个 <compression-code> 使用 , 进行分隔
# 此外每个 <compression-code> 后可以可选指令字段 q=<weight> 表示该种编码格式的随机加权权重, q=<weight> 与 <compression-code> 使用 ;(英文分号)分隔
TE: <compression-code>(; q=<weight>)(, <compression-code>(; q=<weight>))...
# 表示客户端期望在采用分块传输编码的响应中接收挂载字段
TE: trailers
// 示例:多个指令,使用 quality value 语法来表示优先级:
TE: trailers, deflate;q=0.5说明:
- compress:这个名称代表采用了 Lempel-Ziv-Welch (LZW) 压缩算法的传输编码格式。
- deflate:这个名称代表采用了 zlib 结构的传输编码格式。
- gzip:这个名称代表采用了 Lempel-Ziv coding (LZ77) 压缩算法,以及 32 位 CRC 校验的传输编码格式。
- trailers:表示客户端期望在采用分块传输编码的响应中接收挂载字段。
- ;q=<weight>:当多种形式的传输编码格式都可以接受的时候,这个采用了质量价值语法的参数可以用来对不同的编码形式按照优先级进行排序。
兼容性:

图片转自 参考资料[1] 的 TE 词条
6、Transfer-Encoding
Transfer-Encoding 为通用型 HTTP 通讯字段,其即可被包含于 HTTP 请求报文当中,也可以被包含于 HTTP 响应报文当中。其指令值表明了将 entity 安全传递给用户所应当采用的编码形式。
Transfer-Encoding 是一个逐跳传输消息首部,即仅应用于两个节点之间的 HTTP 消息传递,而不是针对所请求的资源本身。在一个多节点连接中的每一段都可以应用不同的Transfer-Encoding 值。如果你想要将压缩后的数据应用于整个连接,那么则需要使用端到端传输消息首部 Content-Encoding 。
当这个消息首部出现在 HEAD 请求的响应中并且这个 HTTP 响应报文没有包含消息体时,那么它代表的意思是该响应将复用相应的 GET 方式请求所对应 HTTP 响应中应答的值(即消息体)。
对于 Transfer-Encoding 字段来说,其重要运用于 HTTP 通讯压缩的 逐跳压缩技术 场景当中。
Transfer-Encoding 的取值有且仅有三种形式:
# 表示客户端在采用分块传输编码的响应中采用 <compression-code> 传输编码类型
# <compression-code> 表示编码格式, 其值可以是标准的 gzip, compress, deflate
Transfer-Encoding: <compression-code>(, <compression-code>) ...
# 表示数据以一系列分块的形式进行发送, 在这种情况下 Content-Length 通讯字段将不被发送
# 取而代之的是在每一个分块的开头将添加以十六进制表示的当前分块的长度, 而后紧跟着 &#39;\r\n&#39;,
# 之后紧跟的是分块内容本身,分块内容后也是紧跟&#39;\r\n&#39;。
# 最后一个分块被称作终止块, 其是一个常规的分块,与其他分块不同之处在于其长度为 0。
# 终止块后面是一个挂载(trailer),由一系列(或者为空)的实体消息首部构成。
Transfer-Encoding: chunked
# 该指令值用于指代自身(例如:未经过压缩和修改)。除非特别指明,这个标记始终可以被接受。
Transfer-Encoding: identity
// 示例:多个指令值采用 , 进行分隔
Transfer-Encoding: gzip, chunked
说明:
- compress:采用 Lempel-Ziv-Welch (LZW) 压缩算法。这个名称来自 UNIX 系统的 compress 程序,该程序实现了前述算法。 与其同名程序已经在大部分 UNIX 发行版中消失一样,这种内容编码方式已经被大部分浏览器弃用,部分因为专利问题(这项专利在 2003 年到期)。
- deflate:采用 zlib 结构 (在 HTTP RFC 1950 中规定),和 deflate 压缩算法 (在 HTTP RFC 1951 中规定)。
- gzip:表示采用 Lempel-Ziv coding (LZ77) 压缩算法,以及 32 位 CRC 校验的编码方式。这个编码方式最初由 UNIX 平台上的 gzip 程序采用。处于兼容性的考虑, HTTP/1.1 标准提议支持这种编码方式的服务器应该识别作为别名的 x-gzip 指令。
- chunked:数据以一系列分块的形式进行发送。 Content-Length 首部在这种情况下不被发送。。在每一个分块的开头需要添加当前分块的长度,以十六进制的形式表示,后面紧跟着 \r\n ,之后是分块本身,后面也是 \r\n 。终止块是一个常规的分块,不同之处在于其长度为 0。终止块后面是一个挂载(trailer),由一系列(或者为空)的实体消息首部构成。
- identity:用于指代自身(例如:未经过压缩和修改)。除非特别指明,这个标记始终可以被接受。
分块编码示例:
分块编码主要应用于如下场景,即要传输大量的数据,但是在请求在没有被处理完之前响应的长度是无法获得的。例如,当需要用从数据库中查询获得的数据生成一个大的 HTML 表格的时候,或者需要传输大量的图片的时候。一个分块响应形式如下:
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
7\r\n
Mozilla\r\n
9\r\n
Developer\r\n
7\r\n
Network\r\n
0\r\n
\r\n
兼容性:
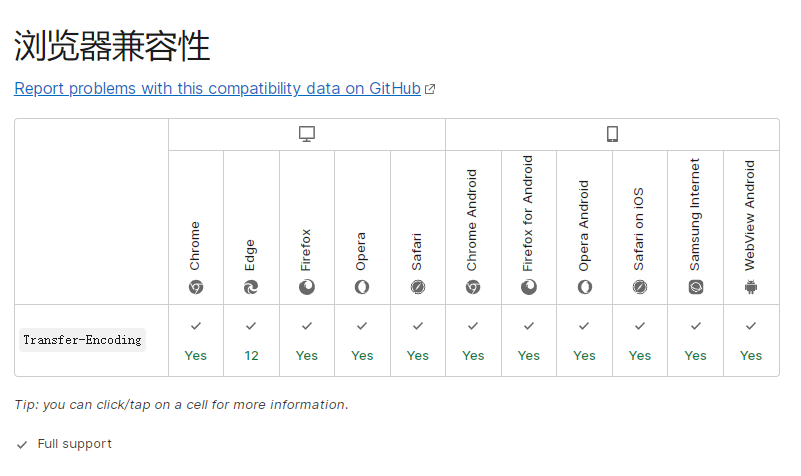
图片转自 参考资料[1] 的 Transfer-Encoding 词条
5、案例五:HTTP 身份验证
在某些情况下,网站所提供的服务具有一定的数据敏感性,不同用户所拥有的权限不尽相同,这时,我们就需要针对用户所拥有的权限进行判别与验证,由于这种场景在实际生产当中非常常见,因此 HTTP 协议专门针对这个场景提供了一套通用的解决方案(即 HTTP 身份验证),遵循 HTTP 通讯规范的浏览器和服务器都会针对 HTTP 身份验证做相应的技术实现,对于前后端及网络相关技术开发人员来说,只需要基于这套通用的解决方案做上层应用开发即可,那么在介绍有关 HTTP 身份验证相关的 HTTP 字段前,就先简单介绍下 HTTP 身份验证 的基础理论吧。
HTTP 身份验证 的基本概念
HTTP 身份验证提供了一个用于权限控制和认证的通用框架。最常用的 HTTP 认证方案是 HTTP Basic authentication。
在 HTTP RFC 7235 中定义了一个 HTTP 身份验证框架,服务器可以用来针对客户端的请求发送 challenge(质询信息),客户端则可以用来提供身份验证凭证。质询与应答的工作流程如下:
①、客户端向服务端发送 challenge 请求
②、服务器端向客户端返回 401 Unauthorized 状态码,并在 WWW-Authenticate 首部提供如何进行验证的信息,其中至少包含有一种质询方式。
③、之后有意向证明自己身份的客户端可以在新的请求中添加 Authorization 首部字段进行验证,字段值为身份验证凭证信息。通常客户端会弹出一个密码框让用户填写,然后发送包含有恰当的Authorization首部的请求。
④、若身份验证成功,则响应返回 200 OK,否则则返回 401 Unauthorized 表示客户端没有通过权限认证
下图为基本身份验证过程中,信息交换须通过 HTTPS(TLS) 连接来保证安全的流程:
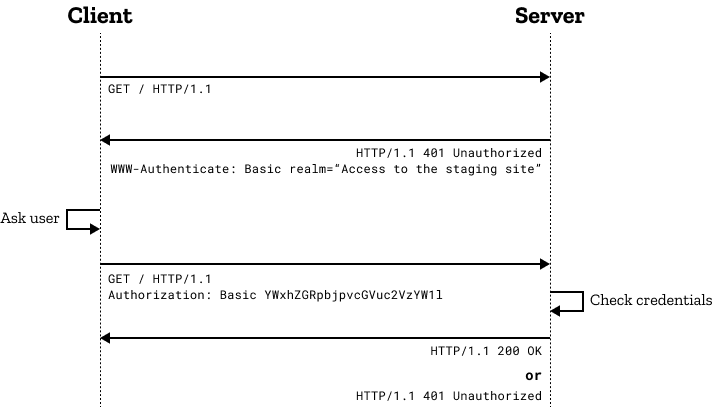
图片转自 参考资料[2] 的 HTTP 身份验证 词条
具体关于 HTTP 身份验证的讲解详细可见 《前端知识链路笔记 - 前后端通讯篇之 HTTP 身份验证(未写完)》或 MDN > Web 开发技术 > HTTP > HTTP 身份验证。
HTTP 身份验证所关联的 HTTP 通讯字段
1、WWW-Authenticate
注意:由于该通讯字段在 MDN 上相关中文文档并没有完整翻译完该字段的内容,由于个人英文水平并不是非常高,可能在翻译过程中存在部分歧义,若有问题还望大佬们及时指正,因此对于本字段的所有描述将附带英文原文描述用于对比说明,最终解释以英文文档为准。 WWW-Authenticate 通讯字段用于 HTTP 响应报文 中,其指令值定义了客户端应该使用何种验证方式(即 challenges,意为:质询)去获取对资源的连接。
The HTTPWWW-Authenticateresponse header defines the HTTP authentication methods (&#34;challenges&#34;) that might be used to gain access to a specific resource.
备注(本人翻译): WWW-Authenticate 通讯字段是 General HTTP authentication framework(通用 HTTP 认证框架) 的一部分,其可以与多种其他认证方案(详见:authentication schemes)一同使用。每个 challenge 都列出了一个服务器所支持的认证方案及该方案所需要附带的认证参数。
备注(英文文档原文):This header is part of the General HTTP authentication framework, which can be used with a number of authentication schemes. Each &#34;challenge&#34; lists a scheme supported by the server and additional parameters that are defined for that scheme type. 对于使用 HTTP 身份验证的服务器将对受保护资源的请求做出 401 Unauthorized 响应。该响应必须包括至少一个 WWW-Authenticate 标头和至少一个 challenges(质询),从而指示客户端可以使用何种身份验证方案及需要提供该种方案所附带的所有附加数据来访问该资源。
A server using HTTP authentication will respond with a 401 Unauthorized response to a request for a protected resource. This response must include at least one WWW-Authenticate header and at least one challenge, to indicate what authentication schemes can be used to access the resource (and any additional data that each particular scheme needs).
对于一个 WWW-Authenticate 通讯字段来说,其允许对应多个质询,对于一个 HTTP 响应来说,其允许包含多个 WWW-Authenticate 标头。服务器还可以在该 HTTP 响应报文的其他响应字段中包含 WWW-Authenticate 头,以表明客户端所提供的凭据可能会影响到响应资源。
Multiple challenges are allowed in oneWWW-Authenticateheader, and multiple WWW-Authenticate headers are allowed in one response. A server may also include the WWW-Authenticate header in other response messages to indicate that supplying credentials might affect the response.
在客户端收到包含 WWW-Authenticate 通讯字段的 HTTP 响应报文之后,客户端通常会提示用户输入身份凭证,然后重新请求资源。对于这个新的 HTTP 请求来说,其将包含 Authorization 通讯字段来向服务器提供用户输入的身份凭证,并针对所选的“质询”身份验证方法进行适当编码。至于究竟该选择何种编码,理论上客户端应选择其理解的最安全的编码方式(但值得注意的是,在某些情况下,所谓“最安全”的编码方法是存在争议的)。
After receiving theWWW-Authenticateheader, a client will typically prompt the user for credentials, and then re-request the resource. This new request uses theAuthorizationheader to supply the credentials to the server, encoded appropriately for the selected &#34;challenge&#34; authentication method. The client is expected to select the most secure of the challenges it understands (note that in some cases the &#34;most secure&#34; method is debatable).
值得注意的是,WWW-Authenticate 通讯字段的语法与其他 HTTP 通讯字段存在部分差异,这是因为 WWW-Authenticate 允许在同一份 HTTP 报文当中多次书写,且不会互相影响,其主要格式有两种:
// 1、在单个 中包含所有的 challenge 质询, 每个质询使用 , 分隔
WWW-Authenticate: challenge1, ..., challengeN
// 2、为每个 challenge 质询独立书写一份 WWW-Authenticate, 每个 WWW-Authenticate 独立成行
WWW-Authenticate: challenge1
...
WWW-Authenticate: challengeN
由于每个 challenge 质询所代表的身份方案不同,因此导致 WWW-Authenticate 指令值所可能取值形式非常多,不过值得注意的是对于每个 challenge 质询 来说,其方案令牌(<auth-scheme>)是必需的,而 realm、token68 和 任何其他参数的存在则取决于所选方案的定义。
A single challenge has the following format. Note that the scheme token (<auth-scheme>) is mandatory. The presence ofrealm,token68and any other parameters depends on the definition of the selected scheme.
// 可能的质询格式(具体取决于方案)
WWW-Authenticate: <auth-scheme>
WWW-Authenticate: <auth-scheme> realm=<realm>
WWW-Authenticate: <auth-scheme> token68
WWW-Authenticate: <auth-scheme> auth-param1=token1, ..., auth-paramN=auth-paramN-token
WWW-Authenticate: <auth-scheme> realm=<realm> token68
WWW-Authenticate: <auth-scheme> realm=<realm> token68 auth-param1=auth-param1-token , ..., auth-paramN=auth-paramN-token
WWW-Authenticate: <auth-scheme> realm=<realm> auth-param1=auth-param1-token, ..., auth-paramN=auth-paramN-token
WWW-Authenticate: <auth-scheme> token68 auth-param1=auth-param1-token, ..., auth-paramN=auth-paramN-token说明:
①、基础通用指令字段
- <auth-scheme>:对于 身份验证方案 来说。一些比较常见的类型有(不区分大小写):Basic, Digest, Negotiate 和 AWS4-HMAC-SHA256。有关更多信息/选项,请参见 HTTP Authentication > Authentication schemes(HTTP 身份验证>身份验证方案)【The Authentication scheme. Some of the more common types are (case-insensitive): Basic, Digest, Negotiate and AWS4-HMAC-SHA256.】
- realm=<realm>:该指令字段为 可选字段,其用于描述受保护区域的字符串。领域(realm)允许服务器对其保护的区域进行分区(如果允许这种分区的方案支持的话),并通知用户需要使用哪个特定的用户名/密码。如果没有指定领域(realm),客户端通常会显示格式化的主机名。【A string describing a protected area. A realm allows a server to partition up the areas it protects (if supported by a scheme that allows such partitioning), and informs users about which particular username/password are required. If no realm is specified, clients often display a formatted hostname instead.】
- <token68>:该字段为 可选字段,代表可能对某些方案有用的令牌。令牌允许66个无保留的URI字符加上一些其他字符。根据规范,它可以保存 base64、base64url、base32 或 base16(十六进制) 编码,有或没有填充,但不包括空白。【A token that may be useful for some schemes. The token allows the 66 unreserved URI characters plus a few others. According to the specification, it can hold a base64, base64url, base32, or base16 (hex) encoding, with or without padding, but excluding whitespace.】
除了<auth-scheme>和 领域(realm) key 值之外,这些授权参数都是特定于每个身份验证方案的。除了</auth-scheme>通常都需要被包含,因此在使用之前需要检查下文所列出的相关规范。
Other than <auth-scheme> and the key realm, authorization parameters are specific to each authentication scheme. Generally you will need to check the relevant specifications for these (keys for a small subset of schemes are listed below).
②、Basic 解决方案附加参数
- <realm>:该指令字段为 可选字段,其表示 HTTP 身份验证当中所需要指定的 领域(realm)【As above.】
- charset=&#34;UTF-8&#34;:该指令字段为 可选字段, 其用于告诉客户端提交用户名和密码时服务器的首选编码方案。值得注意的是,该指令唯一允许的值是不区分大小写的字符串“UTF-8”。该指令值与领域(realm)字符串的编码无关。【Tells the client the server&#39;s preferred encoding scheme when submitting a username and password. The only allowed value is the case-insensitive string &#34;UTF-8&#34;. This does not relate to the encoding of the realm string.】
③、Digest 解决方案附加参数
- <realm>:该指令字段为 可选字段,该指令值用于指示要使用的 用户名/密码 的字符串。其至少应包括主机名,但也可以指明有权访问的用户或组。【String indicating which username/password to use. Minimally should include the host name, but might indicate the users or group that have access.】
- domain:该指令字段为 可选字段,其指令值为引号括起来的并使用空格分隔的 URI 前缀列表,其定义了可能使用身份验证信息的所有位置。如果未指定此密钥,则可以在 web 根目录的任何地方使用身份验证信息。【A quoted, space-separated list of URI prefixes that define all the locations where the authentication information may be used. If this key is not specified then the authentication information may be used anywhere on the web root.】
- nonce: 该指令值用于表示服务器所指定的带引号的字符串,服务器可以使用该字符串来控制特定凭据被视为有效的生存期。每次作出401响应时,必须唯一地生成该信息,并且可以更频繁地重新生成(例如,允许摘要仅使用一次)。该规范包含关于生成该值的可能算法的建议。nonce 值对于客户端是不透明的。【A server-specified quoted string that the server can use to control the lifetime in which particular credentials will be considered valid. This must be uniquely generated each time a 401 response is made, and may be regenerated more often (for example, allowing a digest to be used only once). The specification contains advice on possible algorithms for generating this value. The nonce value is opaque to the client.】
- opaque:服务器指定的带引号的字符串,应在 授权(即Authorization) 中原封不动地返回。这对客户来说是不透明的。建议服务器包含Base64或十六进制数据。【A server-specified quoted string that should be returned unchanged in the Authorization. This is opaque to the client. The server is recommended to include Base64 or hexadecimal data.】
- stale:该指令字段为 可选字段,该指令值为一个不区分大小写的标志,其用于指示来自客户端的上一个请求被拒绝的原因是因为该请求所使用的 nonce太过陈旧。如果该值为 ture,可以使用使用新随机数加密的相同 用户名/密码 重试请求。如果是任何其他值,则表明用户名/密码无效,必须由用户重新请求。【A case-insensitive flag indicating that the previous request from the client was rejected because the nonce used is too old (stale). If this is true the request can be re-tried using the same username/password encrypted using the new nonce. If it is any other value then the username/password are invalid and must be re-requested from the user.】
- algorithm:该指令字段为 可选字段,其用于生成身份验证摘要的算法。有效的非会话值为:&#34;MD5&#34;(如果未指定,则为默认值)、&#34;SHA-256&#34;、&#34;SHA-512&#34;。有效的会话值为:&#34;MD5-sess&#34;、&#34;SHA-256-sess&#34;、&#34;SHA-512-sess&#34;。【Algorithm used to produce the digest. Valid non-session values are: &#34;MD5&#34; (default if not specified), &#34;SHA-256&#34;, &#34;SHA-512&#34;. Valid session values are: &#34;MD5-sess&#34;, &#34;SHA-256-sess&#34;, &#34;SHA-512-sess&#34;.】
- qop:其值为带引号的字符串,该指令值表示服务器支持的保护质量。该指令值必须被提供,并且必须忽略无法识别的选项。【Quoted string indicating the quality of protection supported by the server. This must be supplied, and unrecognized options must be ignored.】
- &#34;auth&#34;: 表 具有身份验证证明【Authentication】
- &#34;auth-int&#34;: 表 具有完整性保护的身份验证【Authentication with integrity protection】
- charset=&#34;UTF-8&#34;:该指令字段为 可选字段,其用于告诉客户端提交用户名和密码时服务器的首选编码方案。唯一允许的值是不区分大小写的字符串 &#34;UTF-8&#34;【 Tells the client the server&#39;s preferred encoding scheme when submitting a username and password. The only allowed value is the case-insensitive string &#34;UTF-8&#34;.】
- userhash:该指令字段为 可选字段,服务器用该指令值表明该服务器是否支持用户名哈希,指定为 &#34;true&#34; 来表示它支持用户名为哈希(默认值为 &#34;false&#34;)【 A server may specify &#34;true&#34; to indicate that it supports username hashing (default is &#34;false&#34;)】
示例:
①、基础认证
仅支持基本身份验证(basic authentication)的服务器可能有一个类似于下列示例的 WWW-Authenticate 响应头:
A server that only supports basic authentication might have aWWW-Authenticateresponse header which looks like this:
# 表示该凭证认证的范围为 Access to the staging site (授予该用户访问暂存站点的权限), 凭证编码格式为 utf-8
WWW-Authenticate: Basic realm=&#34;Access to the staging site&#34;, charset=&#34;UTF-8&#34;接收到包含此通讯字段的 HTTP 响应报文 的用户代理将首先提示用户输入用户名和密码,然后重新请求资源,这一重新请求的报文中将包括经过编码的凭据在 Authorization 通讯字段中,因此该授权头部信息可能看起来像这样:
A user-agent receiving this header would first prompt the user for their username and password, and then re-request the resource: this time including the (encoded) credentials in the Authorization header. The Authorization header might look like this:
# 表示该请求携带了用于 基础身份认证(Basic)的凭证, 凭证哈希码为 YWxhZGRpbjpvcGVuc2VzYW1l
Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l
对于 &#34;Basic&#34; 身份验证来说,凭据首先通过冒号组合用户名和密码(aladdin:opensesame)来构造,然后用 base64 编码算法对结果字符串进行编码(得出 base64 编码字符串:YWxhZGRpbjpvcGVuc2VzYW1l)。
For &#34;Basic&#34; authentication the credentials are constructed by first combining the username and the password with a colon (aladdin:opensesame), and then by encoding the resulting string in base64 (YWxhZGRpbjpvcGVuc2VzYW1l).
备注(自己翻译):另请参阅 HTTP认证 的例子,了解如何配置 Apache 或 Nginx 服务器,以使用 HTTP 基本认证对站点进行密码保护。
备注(原文): See also HTTP authentication for examples on how to configure Apache or Nginx servers to password protect your site with HTTP basic authentication.
②、使用 SHA-256 和 MD5 的摘要认证
备注(自己翻译):这个例子来自 HTTP RFC 7616 &#34;HTTP摘要访问认证&#34; (规范中的其他例子展示了 sha -512、charset 和 userhash 的使用)。
备注(原文): This example is taken from RFC 7616 &#34;HTTP Digest Access Authentication&#34; (other examples in the specification show the use ofSHA-512,charset, anduserhash). 客户端尝试访问URI &#34;http://www.example.org/dir/index.html&#34; 处的文档,该文档通过摘要身份验证受到保护。本文档的用户名是 Mufasa,密码是 Circle of Life(注意每个单词之间的空格)。
当客户端第一次请求文档时,服务器响应报文并不会发送 Authorization 通讯字段。而是会发送一份包含 401 Unauthorized 的响应报文,在这个报文当中包括了服务器所支持的每个摘要算法的质询(challenge),其按其优先顺序排列为(1、SHA256,2、MD5)
The client attempts to access a document at URI &#34;http://www.example.org/dir/index.html&#34; that is protected via digest authentication. The username for this document is &#34;Mufasa&#34; and the password is &#34;Circle of Life&#34; (note the single space between each of the words).
The first time the client requests the document, no Authorization header field is sent. Here the server responds with an HTTP 401 message that includes a challenge for each digest algorithm it supports, in its order of preference (SHA256and thenMD5)
HTTP/1.1 401 Unauthorized
WWW-Authenticate: Digest
realm=&#34;http-auth@example.org&#34;,
qop=&#34;auth, auth-int&#34;,
algorithm=SHA-256,
nonce=&#34;7ypf/xlj9XXwfDPEoM4URrv/xwf94BcCAzFZH4GiTo0v&#34;,
opaque=&#34;FQhe/qaU925kfnzjCev0ciny7QMkPqMAFRtzCUYo5tdS&#34;
WWW-Authenticate: Digest
realm=&#34;http-auth@example.org&#34;,
qop=&#34;auth, auth-int&#34;,
algorithm=MD5,
nonce=&#34;7ypf/xlj9XXwfDPEoM4URrv/xwf94BcCAzFZH4GiTo0v&#34;,
opaque=&#34;FQhe/qaU925kfnzjCev0ciny7QMkPqMAFRtzCUYo5tdS&#34;
当接受到这份 HTTP 响应报文(401 Unauthorized)后,客户端将提示用户输入用户名和密码,然后用一个新的请求进行访问,该请求在 Authorization 通讯字段中对凭证进行编码。如果客户端选择 MD5 摘要,其 Authorization 通讯字段信息可能如下所示:
The client prompts the user for their username and password, and then responds with a new request that encodes the credentials in the Authorization header field. If the client chose the MD5 digest the Authorization header field might look as shown below:
Authorization: Digest username=&#34;Mufasa&#34;,
realm=&#34;http-auth@example.org&#34;,
uri=&#34;/dir/index.html&#34;,
algorithm=MD5,
nonce=&#34;7ypf/xlj9XXwfDPEoM4URrv/xwf94BcCAzFZH4GiTo0v&#34;,
nc=00000001,
cnonce=&#34;f2/wE4q74E6zIJEtWaHKaf5wv/H5QzzpXusqGemxURZJ&#34;,
qop=auth,
response=&#34;8ca523f5e9506fed4657c9700eebdbec&#34;,
opaque=&#34;FQhe/qaU925kfnzjCev0ciny7QMkPqMAFRtzCUYo5tdS&#34;如果客户端选择 SHA-256 摘要,其 Authorization 通讯字段信息可能如下所示:
If the client chose the SHA-256 digest theAuthorizationheader field might look as shown below:
Authorization: Digest username=&#34;Mufasa&#34;,
realm=&#34;http-auth@example.org&#34;,
uri=&#34;/dir/index.html&#34;,
algorithm=SHA-256,
nonce=&#34;7ypf/xlj9XXwfDPEoM4URrv/xwf94BcCAzFZH4GiTo0v&#34;,
nc=00000001,
cnonce=&#34;f2/wE4q74E6zIJEtWaHKaf5wv/H5QzzpXusqGemxURZJ&#34;,
qop=auth,
response=&#34;753927fa0e85d155564e2e272a28d1802ca10daf449
6794697cf8db5856cb6c1&#34;,
opaque=&#34;FQhe/qaU925kfnzjCev0ciny7QMkPqMAFRtzCUYo5tdS&#34;
兼容性:
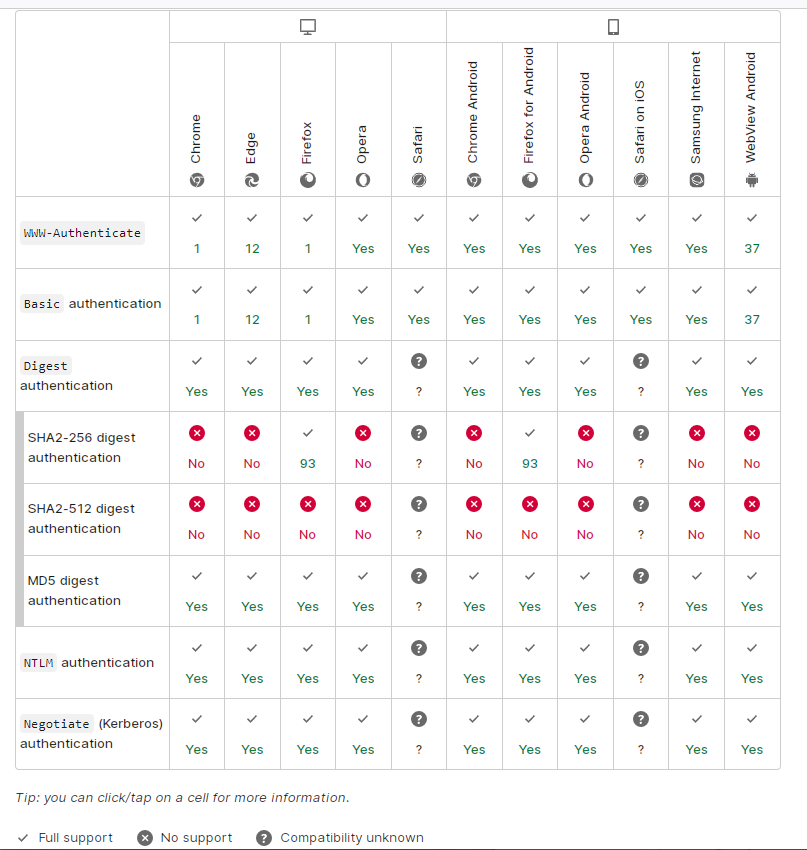
图片转自 参考资料[1] 的 WWW-Authenticate 词条
2、Authorization
注意:由于该通讯字段在 MDN 上相关中文文档并没有完整翻译完该字段的内容,由于个人英文水平并不是非常高,可能在翻译过程中存在部分歧义,若有问题还望大佬们及时指正,因此对于本字段的所有描述将附带英文原文描述用于对比说明,最终解释以英文文档为准。 Authorization 通讯字段用于 HTTP 请求报文 中,其用于提供向服务器验证用户代理的凭据,从而允许访问受保护的资源。
The HTTPAuthorizationrequest header can be used to provide credentials that authenticate a user agent with a server, allowing access to a protected resource.
Authorization 通讯字段通常(但不总是)在用户代理首次尝试请求没有凭据的受保护资源后发送。服务器用至少包含一个 WWW-Authenticate 头的 401 Unauthorized 消息进行响应。这个 WWW-Authenticate 字段用于指示可以使用什么身份验证方案来访问资源(以及客户端使用它们所需的任何附加信息)。用户代理应该从提供的身份验证方案中选择它支持的最安全的身份验证方案,提示用户输入他们的凭据,然后重新请求资源(包括 Authorization 中的编码凭据)。
TheAuthorizationheader is usually, but not always, sent after the user agent first attempts to request a protected resource without credentials. The server responds with a 401 Unauthorized message that includes at least one WWW-Authenticate header. This header indicates what authentication schemes can be used to access the resource (and any additional information needed by the client to use them). The user-agent should select the most secure authentication scheme that it supports from those offered, prompt the user for their credentials, and then re-request the resource (including the encoded credentials in theAuthorizationheader).
备注(自己翻译): Authorization 通讯字段是 通用 HTTP 认证框架 的一部分。它可以与许多 身份验证方案 一起使用。
备注(原文): This header is part of the General HTTP authentication framework. It can be used with a number of authentication schemes.
Authorization 的取值有且仅有一种形式:
# 表示请求将以 <auth-scheme> 身份认证方案进行认证, 并携带 <authorization-parameters> 授权参数
Authorization: <auth-scheme> <authorization-parameters>对于 Basic authentication(基础身份认证方案) 身份认证方案来说,其类似于下列示例:
# 表示该请求使用 Basic 身份认证方案, 并且其携带了 <credentials> 凭证
Authorization: Basic <credentials>对于 Digest authentication(摘要身份认证方案) 身份认证方案来说,其类似于下列示例:
Authorization: Digest username=<username>,
realm=&#34;<realm>&#34;,
uri=&#34;<url>&#34;,
algorithm=<algorithm>,
nonce=&#34;<nonce>&#34;,
nc=<nc>,
cnonce=&#34;<cnonce>&#34;,
qop=<qop>,
response=&#34;<response>&#34;,
opaque=&#34;<opaque>&#34;
说明:
①、通用基础指令值:
<auth-scheme>:定义凭据编码方式的身份验证方案。一些比较常见的类型有(不区分大小写):Basic、Digest、Negotiate 和 AWS4-HMAC-SHA256。【The Authentication scheme that defines how the credentials are encoded. Some of the more common types are (case-insensitive): Basic, Digest, Negotiate and AWS4-HMAC-SHA256.】
备注(翻译): 有关更多信息/选项,请参见 HTTP身份验证>身份验证方案
备注(原文): For more information/options see HTTP Authentication > Authentication schemes ②、基础身份验证(Basic)指令值:
<credentials>:根据服务器所指定的方案进行编码的身份凭证。【The credentials, encoded according to the specified scheme.】
备注(翻译): 有关编码算法的信息,请参见示例:WWW-Authenticate、HTTP Authentication 和相关 HTTP 规范。
备注(原文): For information about the encoding algorithm, see the examples: below, in WWW-Authenticate, in HTTP Authentication, and in the relevant specifications. ③、摘要身份验证(Digest)指令值:
- <response>:证明用户知道密码的十六进制数字字符串。该算法对用户名和密码、realm、cnonce、qop、nc 等进行编码。在说明书中有详细描述。【A string of the hex digits that proves that the user knows a password. The algorithm encodes the username and password, realm, cnonce, qop, nc, and so on. It is described in detail in the specification.】
- username: 其值为一被 引号 包裹的字符串,其包含指定领域的用户名,该字符串可以是纯文本形式,也可以是十六进制表示法中的哈希代码。如果名称包含字段中不允许的字符,则可以使用 username* 代替(不是“as well”)。【A quoted string containing user&#39;s name for the specified realm in either plain text or the hash code in hexadecimal notation. If the name contains characters that aren&#39;t allowed in the field, then username* can be used instead (not &#34;as well&#34;).】
- username*:使用 HTTP RFC 5987 中定义的扩展符号格式化的用户名。仅当名称不能在 username 中编码并且 userhash 设置为 &#34;false&#34; 时,才应使用此选项。【The user&#39;s name formatted using an extended notation defined in RFC 5987. This should be used only if the name can&#39;t be encoded in username and if userhash is set &#34;false&#34;.】
- uri:可被发送的有效 URI 请求。有关更多信息,请参见说明书。【The Effective Request URI. See the specification for more information.】
- realm:所请求用户名/密码的领域(同样,应该与所请求资源的相应 WWW-Authenticate 响应中的值相匹配)。【Realm of the requested username/password (again, should match the value in the corresponding WWW-Authenticate response for the resource being requested).】
- opaque:被请求的资源对应的 WWW-Authenticate 响应中的值。【The value in the corresponding WWW-Authenticate response for the resource being requested.】
- algorithm:用于计算摘要的算法。必须是所请求资源的 WWW-Authenticate 响应中支持的算法。【 The algorithm used to calculate the digest. Must be a supported algorithm from the WWW-Authenticate response for the resource being requested.】
- qop:指示应用于消息的保护质量的令牌。必须与所请求资源的 WWW-Authenticate 响应中指定的值相匹配。【A token indicating the quality of protection applied to the message. Must match the one value in the set specified in the WWW-Authenticate response for the resource being requested.】
- &#34;auth&#34;: 表示具有身份验证证明【Authentication】
- &#34;auth-int&#34;: 表示具有完整性保护的身份验证【Authentication with integrity protection】
- cnonce:客户端提供的带引号的纯 ASCII 字符串值。客户端和服务器都使用它来提供相互身份验证,提供一些消息完整性保护,并避免“选择明文攻击”。有关更多信息,请参见说明书。【An quoted ASCII-only string value provided by the client. This is used by both the client and server to provide mutual authentication, provide some message integrity protection, and avoid &#34;chosen plaintext attacks&#34;. See the specification for additional information.】
- nc:随机数计数。客户端发送当前 cnonce 值(包括当前请求)的请求的十六进制计数。服务器可以使用重复的 nc 值来识别重放请求。【Nonce count. The hexadecimal count of requests in which the client has sent the current cnonce value (including the current request). The server can use duplicate nc values to recognize replay requests.】
- userhash:该指令为可选指令字段,如果用户名已经过哈希处理,则为 &#34;true&#34;。默认情况下为 &#34;false&#34;。【&#34;true&#34; if the username has been hashed. &#34;false&#34; by default.】
警告(原文):Base64 编码 可以很容易地反向获取原始的名称和密码,因此基本身份验证是完全不安全的。因此在使用身份验证时,建议优先使用 HTTPS,在使用基本身份验证时更是如此。
警告(原文):Base64-encoding can easily be reversed to obtain the original name and password, so Basic authentication is completely insecure. HTTPS is always recommended when using authentication, but is even more so when usingBasicauthentication.
兼容性:
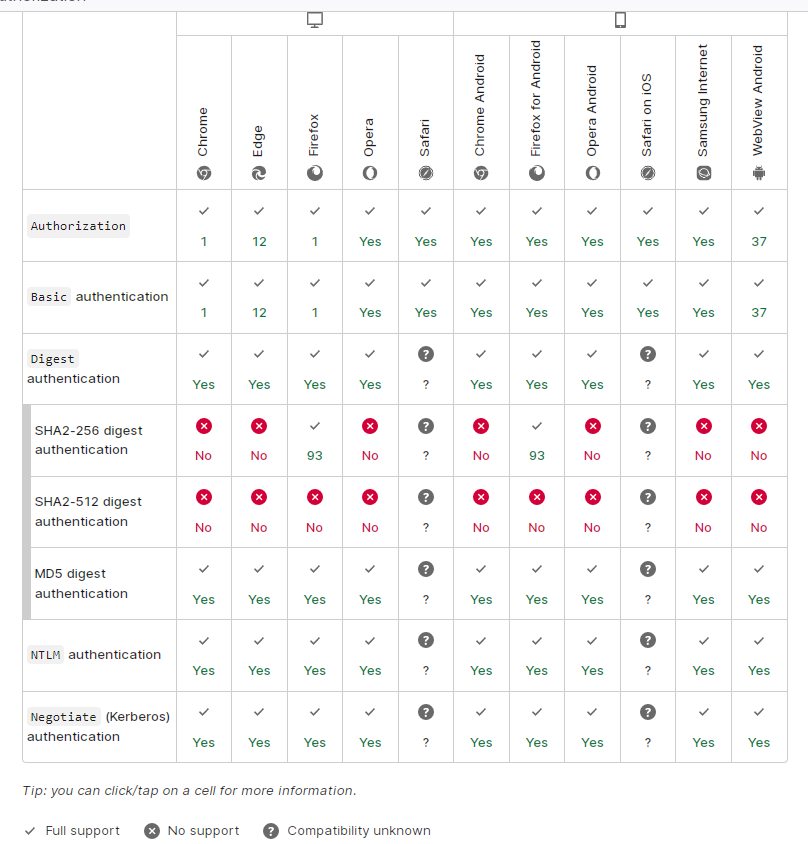
图片转自 参考资料[1] 的 Authorization 词条
3、Proxy-Authorization
Proxy-Authorization 通讯字段用于 HTTP 请求报文中,其指令值包含了用户代理提供给代理服务器的用于身份验证的凭证。Proxy-Authorization 首部通常是在服务器返回了包含 407 Proxy Authentication Required 状态码及 Proxy-Authenticate 通讯字段的响应报文后发送的。
Proxy-Authorization 的取值有且仅有一种形式:
# 表示使用 <type> 身份验证类型, 其凭证信息为 <credentials>
Proxy-Authorization: <type> <credentials>
# 示例:表示 Basic 身份验证类型, 其凭证 base64 编码值为 YWxhZGRpbjpvcGVuc2VzYW1l
Proxy-Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l说明:
- <type>:身份验证类型。一个常见的类型是 &#34;基本验证&#34;(Basic)。 IANA 机构维护了 一系列的身份验证机制。
- <credentials>: 凭证的构成方式如下:
- 将用户名和密码用冒号拼接(例如:aladdin:opensesame)。
- 将拼接生成的字符串使用 base64 编码方式进行编码(例如:YWxhZGRpbjpvcGVuc2VzYW1l)。
兼容性:
由于 MDN 并未收入 Proxy-Authorization 通讯字段相关兼容性报告,因此该字段准确的兼容性未知,不过基于使用场景,【可以近似的将 Authorization 通讯字段的兼容性看作 Proxy-Authorization 通讯字段的兼容性(暂未考究,结论存疑!!!)】
4、 Proxy-Authenticate
Proxy-Authenticate 通讯字段用于 HTTP 响应报文,其指定了客户端获取 proxy server(代理服务器)上的资源访问权限而采用的身份验证方式。代理服务器会先行对携带了身份验证信息的第二次请求进行验证,以便它进一步传递请求。
需要注意是:Proxy-Authenticate 首部需要伴随 407 Proxy Authentication Required 响应状态码一同被发送。
Proxy-Authenticate 的取值有且仅有一种形式:
# 表示客户端应该以 <type> 身份验证类型在 <realm> 安全域做出身份验证
Proxy-Authenticate: <type> realm=<realm>
# 示例:表示客户端应该以 Basic 基础身份验证类型在 Access to the internal site (访问内部站点)安全域下做出身份验证
Proxy-Authenticate: Basic realm=&#34;Access to the internal site&#34;说明:
- <type>:身份验证类型。一个常见的类型是 &#34;基本验证&#34;(Basic)。IANA 机构维护了 一系列的身份验证机制。
- realm=<realm> :对于被保护区域(即安全域)的描述。如果没有指定安全域,客户端通常用一个格式化的主机名来代替。
兼容性:
由于 MDN 并未收入 Proxy-Authenticate 通讯字段相关兼容性报告,因此该字段准确的兼容性未知,不过基于使用场景,【可以近似的将 Authenticate 通讯字段的兼容性看作 Proxy-Authenticate 通讯字段的兼容性(暂未考究,结论存疑!!!)】
参考资料目录
- [1] MDN > Web 开发技术 > HTTP > HTTP Headers
- [2] MDN > Web 开发技术 > HTTP
- [3] Fetch 相关介绍 - WHATWG
- [4] 【方向盘】- Cors跨域系列文章
- [5] HTTP 跨域 - 知乎 Cc.Programmer
- [6] http跨域详解 - segmentfault 小溪流
- [7] HTTP缓存——协商缓存(缓存验证)
- [8] 强缓存与协商缓存(http缓存)
- [9] HTTP 规范 RTC9111 - HTTP Caching
- [10] HTTP 传输内容的压缩
- [11] HTTP认证方式与https简介 - 何必等明天 - 博客园
- [12] HTTP 用户身份认证 - TwinkleG - 博客园
|
|



 发表于 2022-9-21 17:31:52
发表于 2022-9-21 17:31:52