|
|
内容主要自参考自南京大学蒋炎岩老师2022年操作系统课程中的Lec24, Lec25,以及《深入理解计算机系统》,《现代操作系统原理与实现》
本文是笔者对其中部分内容的整理与笔记(实际上整理这篇Blog最初的目的是为了准备某核弹厂的intern面试 总线,中断控制器和DMA
I/O设备的实质如下图所示:
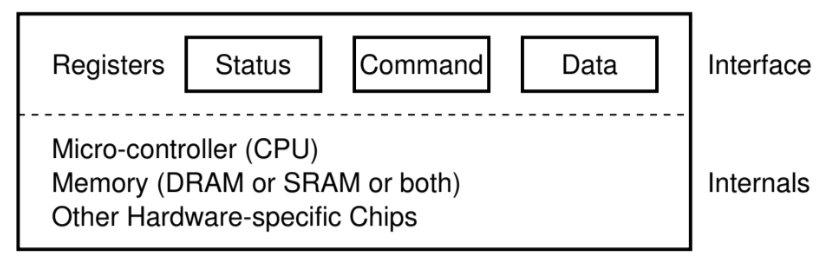
想要和I/O设备的程序可以读取它的状态寄存器,向I/O设备的命令寄存器中写入命令,从I/O设备的数据寄存器中写入/向其中输出数据,在I/O设备的内部存在着用于实现I/O设备的自己的功能的微处理器,以及它的存储器,以及不同类型的I/O设备特有的一些硬件
总线可以理解为一个特殊的I/O设备,有了总线之后当计算机拥有越来越多的外部设备之后,不用再让每个外设都直接连接到CPU,而是可以让CPU和总线连接,所有可以使用的外部设备通过主板上的插槽连接到总线上,外部设备通过总线和CPU进行通信,这样的设计相当于为CPU设计了一层抽象,即CPU可以通过总线与任何的外部设备连接,而不需要CPU和一个个外部设备单独连接,如下所示:
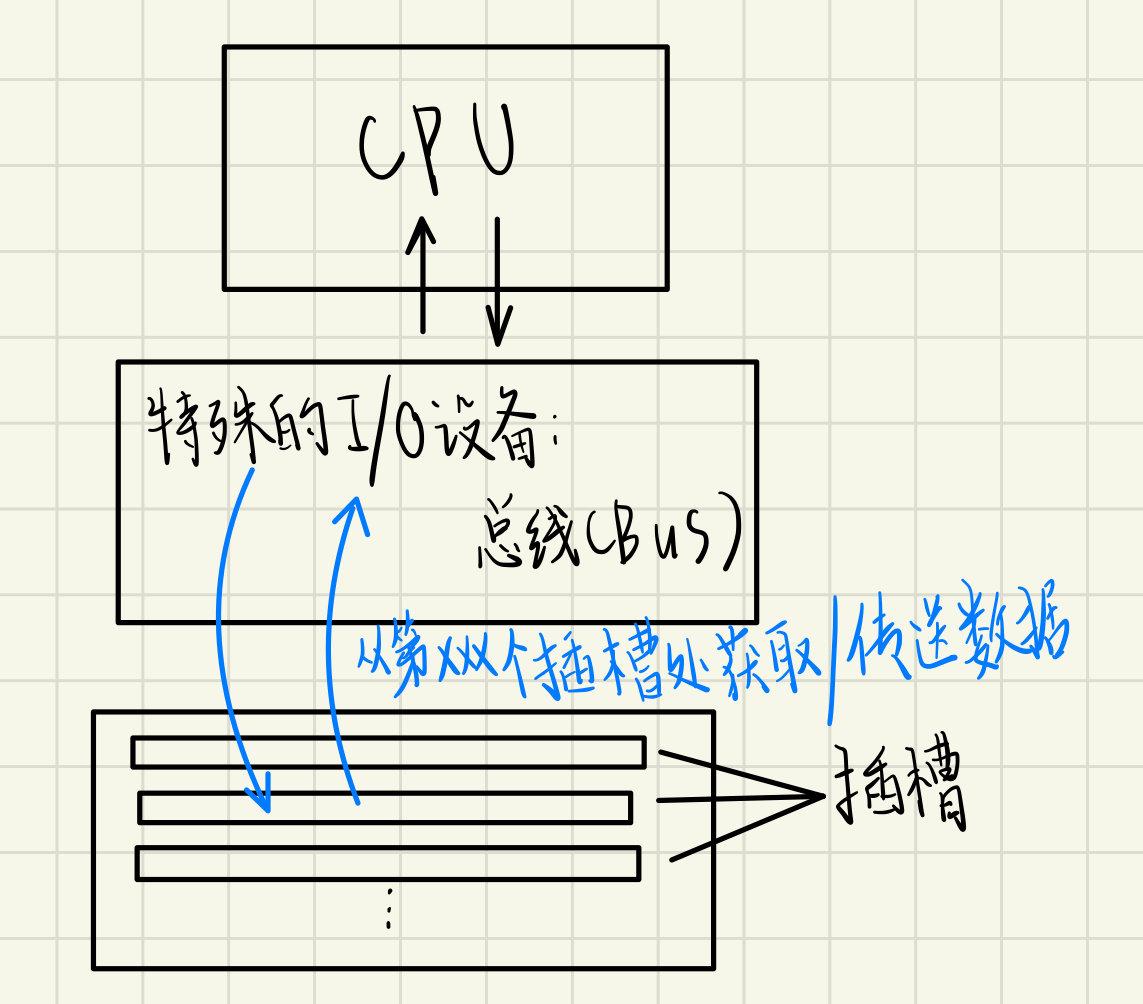
DRAM内存也可以连接到总线上,这就构成了一个简单的计算机
早期CPU除了连接总线,还会连接中断控制器(比如说Intel 8259可编程中断控制器,可以级联以扩展中断源的数量,也可以设置中断源的优先级,也可以屏蔽特定中断源),中断控制器连接着中断源
现代计算机中一般存在着如下两种高级中断控制器(Advanced PIC)
- local APIC:每个CPU都有一个,时钟中断由它来处理,处理器与处理器之间的中断(IPI,Inter Processor Interrupt)也由它来处理(IPI的应用场景:多核的计算机系统在reset的时候只有一个核会启动,这个核会发出IPI将其他处理器唤醒;在两个核上运行的两个线程T1和T2,如果T1线程调用了mmap系统调用,那么T1所在的CPU的TLB就需要被刷新,但是T2和T1是共享地址空间的,此时T2所在核的TLB没有被刷新,如果此时T2想要访问地址空间里刚刚mmap的那一片区域,就会发生page falut,因此为了避免这种情况,我们需要让T1所在核向T2所在核发送一个IPI,从而让T2所在核刷新TLB,这也被称为TLB shoot down,在具有很多个CPU的计算机系统当中,TLB shoot down会造成一些性能问题)
- I/O APIC:整个计算机系统中只有一个,连接到外部的中断线,如果总线上有中断请求的话会传给I/O APIC,I/O中断就由它来处理
DMA是除了总线和中断以外的一种非常特殊的I/O设备,DMA解决了一个中断没能完全解决的问题:如何更快完成大规模数据拷贝
假设程序想拷贝1GB的数据到磁盘,相对于CPU,总线很慢,如果我们想让程序以循环的方式一点一点通过总线把数据拷贝到磁盘,那么开销会非常巨大
如果系统当中有另外一个比较Tiny的CPU,它只负责执行memory copy(从内存读一个字节到这个Tiny CPU,再从这个Tiny CPU把刚刚读到的字节传入总线,反过来也需要做到,从内存到内存的数据拷贝也需要做到),不需要支持某个完整的ISA,当计算机系统的某个CPU正在执行一个比较耗时且简单的操作的时候,可以把这个操作交给刚刚说的Tiny CPU来做,等到Tiny CPU把任务做完了再给最开始执行任务的CPU的发中断
因此DMA的本质是通过在系统里增加一个CPU来加速从内存到总线的数据搬运,DMA的外接线直接被连接到I/O总线和内存上
GPU和异构计算
前面有说到DMA是一个专门执行"memcpy"程序的CPU,显卡也是一个特殊的I/O设备,它只负责画图,并且比CPU还要快
显示图像的时候需要在4K的画布上算出每个像素点的RGB值,使用循环的方式来计算的话很难达到60FPS的刷新率
早期任天堂的红白机可以做到在极其有限的硬件条件下的60FPS刷新率,这意味着需要在每秒只能执行很有限数目的指令的同时在屏幕上画很多个点,如果用循环的方式来打印然后画点的话不可能做到,因为很有可能一秒之内那么多次空循环的执行不完

红白机为了解决刷新率的问题引入了PPU(Picture Processing Unit,类似于现代的GPU),红白机的游戏画面由许许多多的小方块构成,
PPU会管理这些小方块,这些小方块位于PPU的内存里(相当于显存)
PPU会先绘制一个很大的背景,在背景中裁切出一个view point,这个view point就是当前我们看到的东西,并且PPU支持view point的移动,这也是卷轴式的动画怎么来的
除了view point本身,PPU还会将若干个上文所说的小方块在view point中显示出来
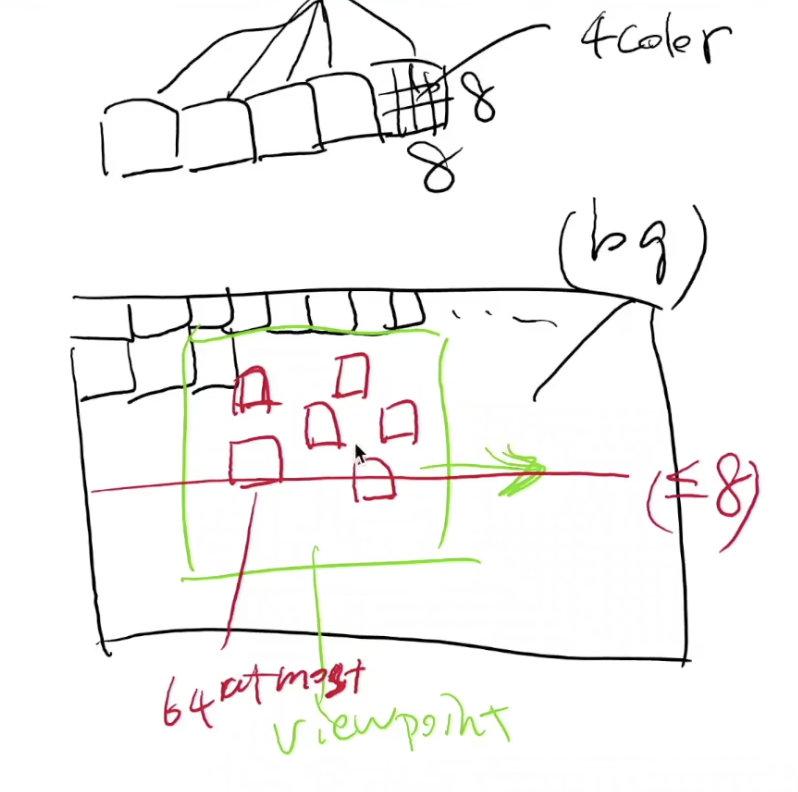
CPU在每一个frame(如果是60HZ刷新率的话就是1/60秒)生成像下面这样一系列的指令:
“把第i号方块放到(x, y)坐标处,并且采用a号调色板对应的配色”,“把view point放到坐标为(x, y)的位置”
PPU本质上和CPU一样都是可以执行指令的处理器,但PPU功能有限,只能执行上一段话中所描述的关于绘图的指令,然后将画好的图形输出到显示器的物理接口(比如说VGA)上
回到刚才红白机如何实现高刷新率的问题,既然在一秒钟之内CPU无法执行太多的指令,那么我们就不让CPU在有限的时间内打印绘图,而是让CPU执行相对少量的指令生成对PPU的控制指令,然后交给PPU去绘图,PPU可以快速地执行收到的指令,移动设定好的方块和view point从而完成绘图,满足高刷新率的要求
红白机中的PPU就是现代GPU的雏形,现代GPU可以执行很多更复杂的程序,比如说矩阵计算,NVIDIA的CUDA就可以作为提供给应用程序的接口完成这种事情,CUDA的编译器会把程序编译成两个部分,一部分是在本地操作系统环境下执行的ELF文件,另一部分是可以在GPU上执行的代码,现代GPU可以理解成拥有好多个"CPU"的计算系统(如下所示,每个核心都有自己的Cache和Memory Hierarchy,但是GPU的指令集和CPU的指令集略有不同,GPU属于可以做乘法和加法的向量处理器),
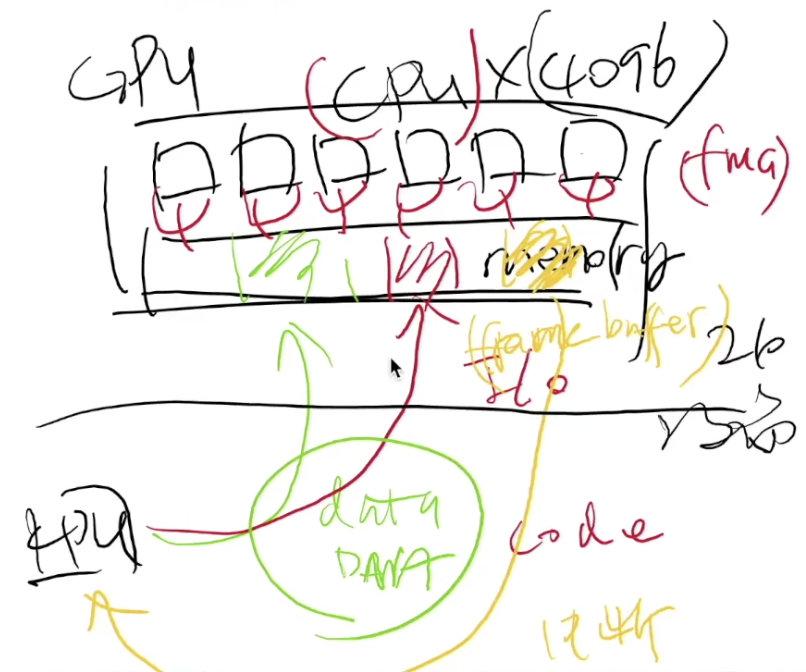
并且拥有巨大的“内存”(也就是显存),在CPU上运行的程序负责把GPU所需要的数据(有可能是一个很大的矩阵,或者是深度学习当中需要训练的数据)通过DMA的方式送入显存,再把GPU需要执行的程序也送入显存,GPU执行完程序之后会把计算结果写回到显存里,写回操作完成之后GPU会给CPU发一个中断,因此GPU既可以看作是一个I/O设备,也可以看作是另一台计算机
随着现代计算机体系结构的发展,功耗墙的出现引出了多核架构,但是CPU核心数多到一定程度之后带来的多cache一致性的问题也会对性能造成很大的影响,这些都是处理器设计的瓶颈所在,现代计算机系统中往往会在同一个芯片(SOC, System on Chip)上集成各种处理器:CPU,GPU,NPU(Neural network Processing Unit,专门用来做神经网络的推测)
当一个计算任务到达之后,SOC会选择让能效比最高的那个处理器来执行这个计算任务,这就是异构计算
设备驱动原理
在CPU以及操作系统的眼中,外部的I/O设备其实就是一组寄存器和一组相应的协议(规定给哪个寄存器写入哪种数据,I/O设备会做出什么样的反应),不同的设备有着不同的协议,外部设备本身就存在着一定的复杂性(比如说功能很多的打印机),操作系统直接把设备以寄存器的形式暴露给应用程序,让应用程序按照外部设备的协议来编写并不是一个很好的选择(这会很大程度上提升程序编写的复杂度,出错后会造成很严重的后果,比如说打印机打印错误浪费很多纸张),因此需要对设备做抽象,让应用程序无需访问设备的寄存器,只需要通过一个尽可能通用的API来访问设备
设备驱动程序存在的意义就是把所有的I/O设备共有的功能提取出来,使得应用程序可以用同样的接口,屏蔽掉复杂的细节,从而完成对I/O设备的抽象
在Unix/Linux操作系统的世界当中,外部设备分为两大类:character device和block device,character device是一个字节流(Byte Stream),不同于内存或者磁盘这种read-only情况下连续两次读取同一个位置会得到相同的值的设备,它有点像一个管道,我们可以从其中拉取数据,比如说鼠标和键盘,用户的按键的序列就是一个字节流,驱动程序读取键盘的按键序列这个字节流就可以得到用户的input。与之相反,磁盘这种block device更像是一个字节数组(Byte Array)。显卡是一个特别的设备,显卡的控制器是一个字节流,显存是一个字节数组
结合如上所述,对于一个设备来讲,从操作系统的视角来看,需要实现它的如下三种抽象,或者说是如下的三个系统调用:read, write, ioctl(即i/o control,用来读取或设置设备的状态,更简单的说,用来配置设备:每个设备都有一些属于它的特殊的控制选项,比如说显卡可以设置它的分辨率,打印机可以人为控制它的纸盘,键盘可以开启跑马灯、键盘宏功能),驱动程序的代码就是用来建立这三种抽象,从这个角度来看,驱动程序和shell很像,shell会将用户输入的命令翻译成一组系统调用
通过open系统调用(比如说open("/dev/urandom"))可以激活设备的驱动程序,并且返回一个文件描述符(假设叫fd),在通过read(fd)这样的系统调用从其中读数据时,操作系统就会调用这个设备相应的驱动程序
Unix系统的/dev目录中的设备不都是真实存在的,比如说dev/null(其实dev/urandom也是,它可能是真正可以生成随机数的硬件,也可能是用软件来模拟的),如果某些程序的输出我们不想要了,那么就可以把它重定向到/dev/null,/dev/null这个现实中不存在的设备的驱动程序的实现很简单,对任何通过write调用传来的写请求,它立刻返回写入成功,对于read系统调用传来的读请求立刻返回0
设备驱动程序是Linux内核中最多也是质量最低的代码(稍有不慎就有可能因为指针的问题kernel panic,并且由于某些设备比较稀有导致对它的驱动程序进行测试的场景与机会都不多),目前Linux系统的一大发展趋势就是将驱动程序从内核空间转移到用户空间
Linux上的虚拟设备
假设我们要实现一个核弹发射器的驱动程序(此处不得不佩服jyy的脑洞 ,程序里定义的password可能也是个彩蛋吧2333),

jyy老师提供的代码地址在这一页sildes里,代码最后的
module_init(lx_init);
module_exit(lx_exit);这一段用来标记内核中这个驱动对应的模块的起点和终点,这和最开始include的Linux内核中的module库有关,这段设备驱动在被编译完了之后会生成类似于.so这样的shared object的可以动态加载的动态链接库(实际上是.ko : kernel object, Linux内核启动的时候内存里可能没有这个模块,可以在Linux启动之后通过一个系统调用把这个模块加载到内核里),module_init和module_exit这两个宏存在的意义是可以在模块init和unload的时候分别调用lx_init函数与lx_exit函数
lx_init函数会利用Linux内核提供的API把设备注册上去
static int __init lx_init(void) {
dev_t dev;
int i;
// allocate device range
alloc_chrdev_region(&dev, 0, 1, "nuke");
// create device major number
//给这个设备分配一个主设备的设备号
dev_major = MAJOR(dev);
// create class
//创建一个设备的类别
lx_class = class_create(THIS_MODULE, "nuke");
//创建MAX_DEV个“核弹发射井”
for (i = 0; i < MAX_DEV; i++) {
// register device
//给每个设备的数据做初始化
cdev_init(&devs.cdev, &fops);
cdev.owner = THIS_MODULE;
cdev_add(&devs.cdev, MKDEV(dev_major, i), 1);
//创建一个这个类型的设备
//MKDEV中的第一个参数是主设备号,第二个参数是小的设备号
//&#34;nuke%d&#34;是使用printf语法来指定设备名字
device_create(lx_class, NULL, MKDEV(dev_major, i), NULL, &#34;nuke%d&#34;, i);
}
return 0;
}lx_exit中要执行上述操作的反操作
Linux当中一切皆文件,因此只需要如下的file_operations结构体就可以注册设备驱动程序
static struct file_operations fops = {
.owner = THIS_MODULE,
.read = lx_read,
.write = lx_write,
};在前面的lx_init的code_init函数中会把这种结构体作为参数传入,这样的话通过系统调用读写这个设备的时候控制流就会走到我们所注册的函数那里(可以用strace命令验证),lx_read中有一些error checking以确保驱动程序的安全性
工业界真实的驱动程序的file_operations结构体中会注册更多的函数:
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
int (*mmap) (struct file *, struct vm_area_struct *);
unsigned long mmap_supported_flags;
int (*open) (struct inode *, struct file *);
int (*release) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*flock) (struct file *, int, struct file_lock *);
...其中和ioctl有关的函数有两个:

早期使用BKL的架构下,在持有锁的情况下访问低速的设备会很影响性能,因此后来有了unlocked_ioctl在无锁的情况下进行ioctl,compact_ioctl存在的意义是为了在64位机器上运行32位的程序,因为32位的程序中的ioctl是32位的,涉及指针相关的时候就会有很多麻烦 |
|



 发表于 2022-9-21 04:31:26
发表于 2022-9-21 04:31:26