|
|
1. 前言
说起在实时游戏中应用流体模拟,2019年GDC上圣莫妮卡工作室分享过他们如何在战神4中使用流体模拟来实现可交互风场。而在竞争日益激烈的手游市场,策划和美术们自然也想把类似的功能加入到自家产品以提高竞争力(还真是敢想呢( ˚ཫ˚ ))。
战神4中的方案使用了三维纹理存储空间中流体的速度场(基于欧拉视角下的流体模拟)。一方面三维纹理的采样对移动端这种带宽本就不太充裕的平台会造成不少的压力;另一方面流体模拟过程中需要使用Compute Shader对三维纹理实施注入,而安卓平台对Compute Shader良莠不齐的兼容性也是一个必须考虑的不稳定因素。
所以想要在手游产品中应用流体模拟,一个可能方案是退化到二维的流体模拟,毕竟除了少部分飞行类的游戏外,大部分游戏中的角色主要在地面运动,使用二维的流体模拟来表现角色所在高度附近的流体流动,也未尝不可。
退化到二维空间后,我们就可以放心大胆地使用二维纹理来保存流体场的状态了,并且对二维纹理的读写操作也可以直接使用兼容性更好的Pixel Shader。
在下面展示的案例中,我使用了二维流体模拟来驱动地面附近的粒子。
由于二维的流体模拟只能给出水平面上的速度,而粒子是允许在三维空间运动的,因此缺失的Z轴速度,我使用了一个随当前位置流体速度与离地高度缩放的Curl Noise作为Z轴速度的补充。
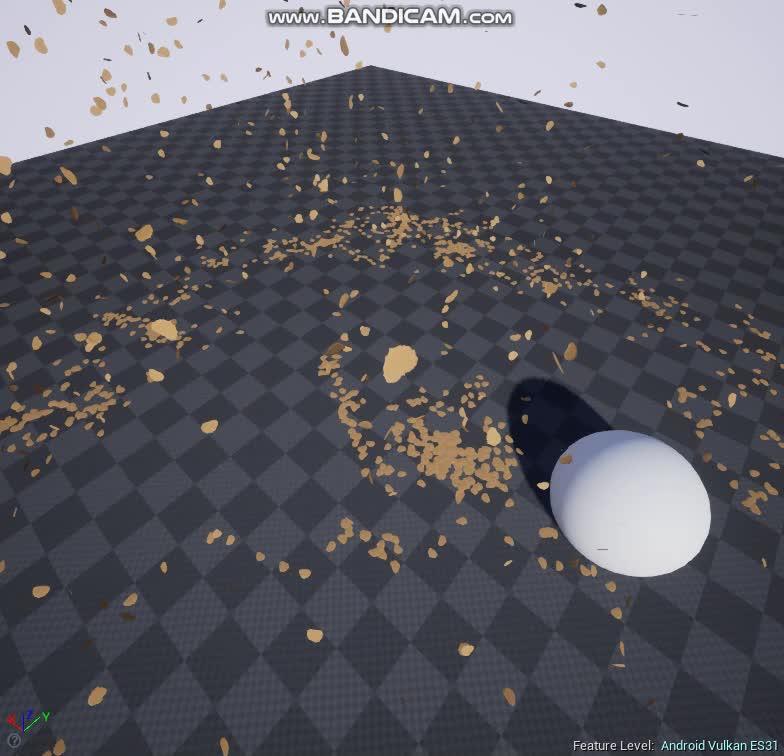
二维流体模拟与粒子系统
https://www.zhihu.com/video/1541515592565846016
其实不难想象,除了粒子系统外,种植在地表上的植被等其他系统也可以访问模拟结果,为场景增加更多的可交互性。
文章的前半部分,我想简要地介绍一些背景知识,而在后半部分会分享一种我了解到的加速二维流体模拟的方案,使得机制在移动端能够落地。
<hr/>2. 方案
尽管咱们把模拟的空间从三维退化到二维,数据结构也从三维纹理改为对移动端更友好的二维纹理,但移动端GPU在使用一般的求解NS方程的方案时,仍会面临不小的挑战。
Fast Fluid Dynamics Simulation on the GPU, GPU Gems Chapter 38 [1] 是一篇关于在GPU上实现二维流体模拟的经典文章,文章给出了如何在GPU上求解“不可压缩NS方程”的经典步骤。
即对于方程
\frac{\partial\vec{u}}{\partial{t}}=-(\vec{u}\cdot\nabla)\vec{u}-\frac{1}{\rho}\nabla{p}+\nu\nabla^2\vec{u}+F
\nabla\cdot\vec{u}=0 我们最终要求得一个符合上式且散度为零(无压缩)的速度场 \vec{u}
求解的过程会将方程分成几步处理:
Advection 平流项,求解平流方程 \frac{\partial\vec{u}}{\partial{t}}=-(\vec{u}\cdot\nabla)\vec{u} 。
平流在实时游戏中,一般会从简使用Forward Euler(&#34;RK1&#34;)处理,即[1]中给出的方案。
p=p-u(p)*dt
Advection一般不会是求解中的性能热点,其误差在游戏这种“只要看起来是对的就行”的应用场景也能接受。
所以这里不会讨论其他误差和数值粘性更小的方案。
External Force 外力项, F, \frac{\partial\vec{u}}{\partial{t}}=F。
剩下的两项,对于整个流体场而言,是两组微分方程组,通常会使用一些数值方法来迭代求解
Viscous Diffusion 粘性扩散项,\frac{\partial\vec{u}}{\partial{t}}=\nu\nabla^2\vec{u}
Pressure 压力项, \frac{\partial\vec{u}}{\partial{t}}=-\frac{1}{\rho}\nabla{p}
而大部分实时游戏模拟的主要是空气,水流等低粘性流体,所以为了减少运算量,秉承我们能省则省,能阉割则阉割的“优良传统”,我们舍弃掉粘性项。
舍弃掉粘性项的NS方程,亦可称为欧拉方程。
\frac{\partial\vec{u}}{\partial{t}}=-(\vec{u}\cdot\nabla)\vec{u}-\frac{1}{\rho}\nabla{p}+F
\nabla\cdot\vec{u}=0 此时,阻碍我们求解欧拉方程的唯一障碍就是 —— 使用迭代法求解压力项,这也是整个流程的热点所在。
大部分文献,把求解压力项的过程称为Projection,投影。
具体的操作,我们可以简单推导一下:
\frac{\partial\vec{u}}{\partial{t}}=-\frac{1}{\rho}\nabla{p}
左边写成有限差分的形式: \frac{\vec{u}-\vec{u^*}}{\Delta{t}}=-\frac{1}{\rho}\nabla{p}
其中 \vec{u^*} 是经过平流,外力后的流体速度场,该速度场的散度一般不为零,也就是说该速度场是存在压缩的。
\vec{u} 是最终我们要求解的无压缩的,散度为零的速度场。
进行一些简单移项,把我们要求的速度场 \vec{u} 留在等号的一侧
\vec{u}=\vec{u^*}-\frac{\Delta{t}}{\rho}\nabla{p} ,由于压力梯度场前的 \frac{\Delta{t}}{\rho} 可以认为是一个常数,为了方便表示,可以把它乘到梯度场中
\vec{u}=\vec{u^*}-\nabla{p^{**}} , \nabla{p^{**}} 是一个带缩放的压力梯度场。
上面这个式子想说,一个存在压缩的速度场 \vec{u^*} ,与另一个无散度的速度场 \vec{u} 之间,相差一个梯度场(Helmholtz Hodge Decomposition)。
从感性上理解公式 \vec{u}=\vec{u^*}-\nabla{p^{**}}
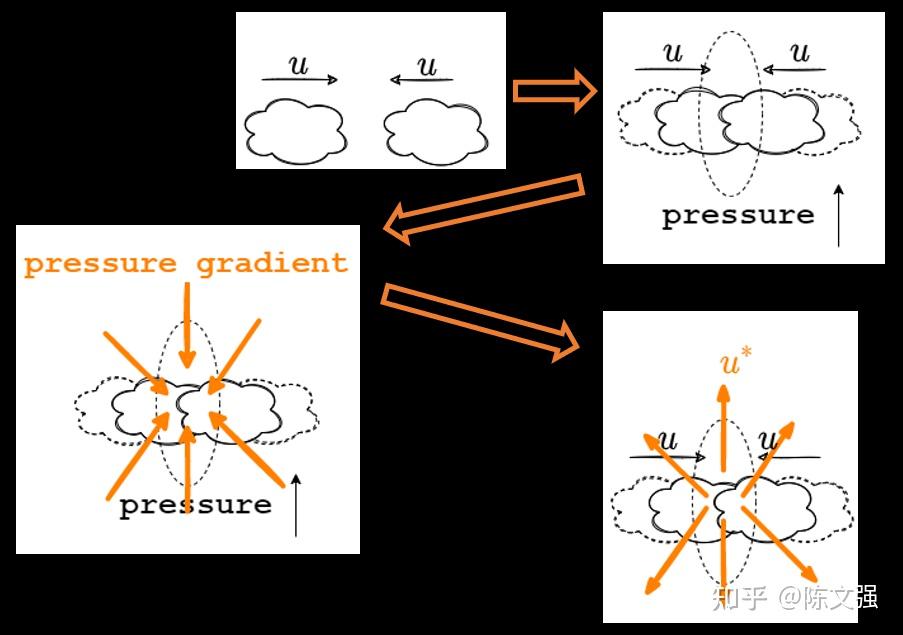
假设有两团气体相对流动,当他们相遇时,中间的部分会挤压,产生压力。此时如果考虑该位置的压力梯度,由于中间部分的压强较大,因此压强梯度的方向由四周指向挤压的部分。气体想要从压缩的状态回到无压缩的状态的话,修正的速度方向应该为梯度的反方向,亦即 \nabla{p^{**}} 前的负号。
在经过平流,外力等操作后,我们得到了 \vec{u^*} ,为了得到最终的无散度速度场 \vec{u} ,现在的目标是求得梯度场 \nabla{p^{**}} 。
目前为止,我们手上还有 \vec{u} 散度为零的条件还没有用上,对移项后的公式 \vec{u}=\vec{u^*}-\nabla{p^{**}} 两边求散度
\nabla\cdot\vec{u}=\nabla\cdot\vec{u^*}-\nabla^2{p^{**}} ,由于 \nabla\cdot\vec{u}=0 ,对公式简单化简并移项,得到
\nabla\cdot\vec{u^*}=\nabla^2{p^{**}}
上式中 \vec{u^*} 是已知的,那么我们就可以解出来 p^{**} ,最后从 \vec{u^*} 减去其梯度后,就能得到最终我们要解的 \vec{u} 。
<hr/>上面我们大体介绍了求解不可压缩的欧拉方程的步骤。
其中,最关键(麻烦)的一步是通过求解微分方程组,\nabla\cdot\vec{u^*}=\nabla^2{p^{**}}得到压力场 p^{**}
实时应用中,我们一般通过一些数值迭代方法(例如Gauss-Siedel或者Jacobi)来求解上面这个方程。
在计算机中解决问题,第一步当然是把问题离散化,即对于使用二维网格表示的流体场中的任意位置 (i,j)
满足公式:\frac{(u^*_x)_{i+1,j}-(u^*_x)_{i,j}+(u^*_y)_{i,j+1}-(u^*_y)_{i,j}}{l}=\frac{p_{i+i,j}+p_{i-1,j}+p_{i,j+1}+p_{i,j-1}-4p_{i,j}}{l^2}
上式中, (u^*_x)_{i,j} 表示速度场 \vec{u^*} 在位置 (i,j) 处沿 x 轴方向的速度, (u^*_y)_{i,j} 同理, l 表示网格的宽度。
等号两侧分别是散度 \nabla\cdot\vec{u^*} 与拉普拉斯算子 \nabla^2{p^{**}} 的差分表示,见[1]。
速度场 \vec{u^*} 已知,我们可以算出其散度,所以上面的公式可以改为
\frac{p_{i+i,j}+p_{i-1,j}+p_{i,j+1}+p_{i,j-1}-4p_{i,j}}{l^2}=div_{i,j} , div_{i,j} 表示速度场 \vec{u^*} 在位置 (i,j) 处的散度(Divergence)。
对于流体场中的所有位置,即 (0,0),(0,1)...(i,j)...(n-1,n-1) 其位置的压力都需要满足上面的方程。
把这些方程联立起来就能得到一个关于流体场各处压力 p_{i,j} 的线性方程组。
\begin{cases} ... \\ \frac{p_{i,j}+p_{i-2,j}+p_{i-1,j+1}+p_{i-1,j-1}-4p_{i-1,j} }{l^2}=div_{i-1,j} \\ \frac{p_{i+1,j}+p_{i-1,j}+p_{i,j+1}+p_{i,j-1}-4p_{i,j} }{l^2}=div_{i,j} \\ ... \end{cases}
很多文献为了表示方便,也会选择把这个方程组写成矩阵方程的形式 Ap=D ,A 是方程组中,未知数 p_{i,j} 的系数矩阵, p 是未知数 p_{i,j} 组成的列向量, D 同理,是场中各处位置 div_{i,j} 组成的列向量。
如前所述,为了高效求解这个方程组,一般会使用数值解法进行迭代求解。
这里我们继续沿用[1]中的方法,使用Jacobi迭代法求解。
把方程 \frac{p_{i+i,j}+p_{i-1,j}+p_{i,j+1}+p_{i,j-1}-4p_{i,j}}{l^2}=div_{i,j} 按照Jacobi迭代法的要求,改写为
p^{k+1}_{i,j}=\frac{p^{k}_{i+i,j}+p^{k}_{i-1,j}+p^{k}_{i,j+1}+p^{k}_{i,j-1}-l^2*div_{i,j}}{4} , k 是迭代次数。
在GPU上实现时,一般会使用两张Render Target作为Ping-Pong Target反复切换读写来实现迭代法。
这对于移动端这种基于Tile Based Rendering的低带宽平台来说是非常不利的。
每次切换Render Target,都需要把Tiled Memory写回显存,并且执行资源的内存布局转换(Resource&#39;s memory layout transition),以便当前作为RTV的纹理在下次迭代时能以SRV的形式绑定到管线被Shader采样。
迭代的次数越多,我们求解得到压力场越准确,但切换Render Target带来的Overhead也越高。
这也说明了,使用迭代法来求解压力场,是整个求解欧拉流体方程中的瓶颈所在。
<hr/>引擎自带的Volumetric插件中,有一个现成的2维流体模拟的例子,正好可以作为我们的测试床。
以下是使用32次迭代求解压力场时得到的模拟效果。

迭代法求解压力场 | 迭代次数 32
https://www.zhihu.com/video/1547255558704398336
各个阶段的耗时,可以看到在经过平流,对平流后的速度场计算散度之后,就会经历一个32次的漫长迭代,迭代计算得到的压力场在最后计算梯度,以修正速度场。迭代计算是整个流程中的绝对性能瓶颈。
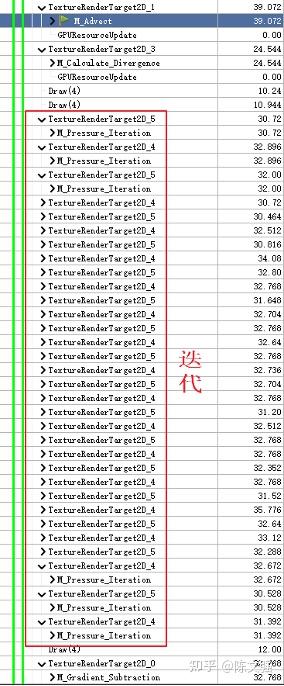
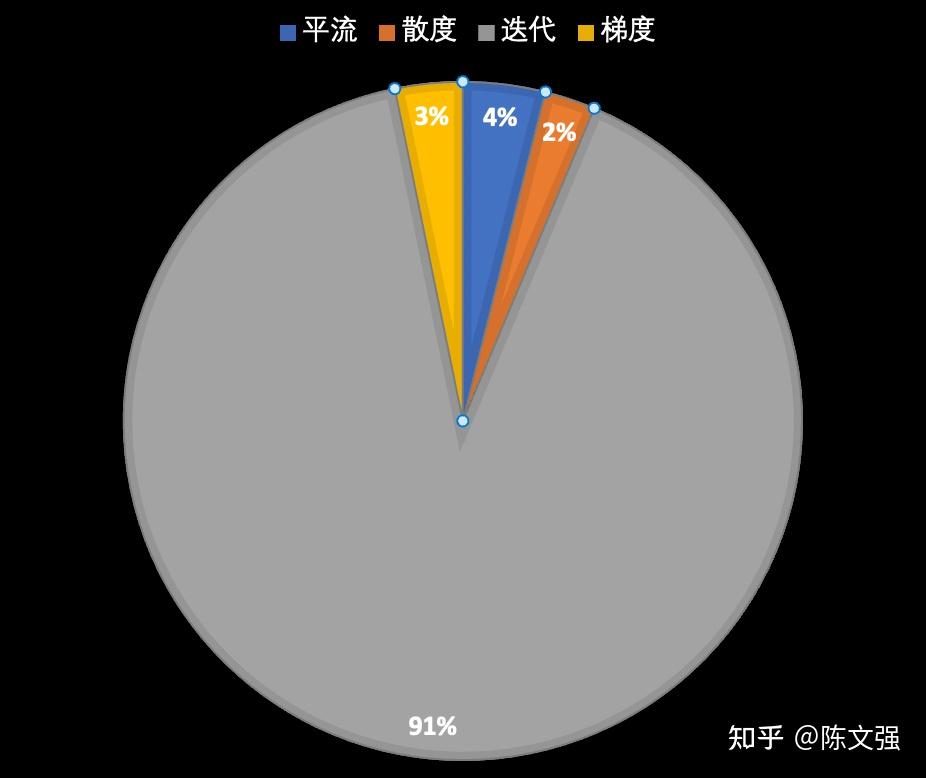
既然如此,那我们简单粗暴地减少迭代次数就能解决问题吗?
下面是一个迭代次数为3的效果,可以明显看到,颜料在流动一段距离后会迅速消失,对整体的流动效果由很大的影响。
迭代法求解压力场 | 迭代次数 3
https://www.zhihu.com/video/1547258539084582912
主要的原因是迭代次数减少了,压力场存在较大的误差,用这个压力场修正得到的速度场仍然有较大的散度,颜料就会在这些散度不为零的位置产生压缩。
<hr/>迭代次数多了,性能不好;迭代次数少了,效果不好。(;´༎ຶД༎ຶ`)
那是否能在两者中找到一个合适的平衡,尤其要适合移动端这种性能弱鸡平台的方案呢。
既然移动端对于切换Render Target这件事情比较敏感,那优化的方向自然是朝着减少Render Target切换的方向发展。
在此之前,我能想到的是把迭代次数设定在一个不多不少的折中状态,在保证效果的同时减少迭代的次数(是个人都能想到好吗( Ꙭ))。
但某天我在网上冲浪的时候,发现一篇文章的方案能比较好地解决这个问题:
Fast Eulerian Fluid Simulation In Games Using Poisson Filters, SCA 2020 [2] 这篇文章的方案,能够通过固定两次的可分离滤波(Separable Filtering),比较精确(量化误差按照文章里的说法,大概是83%左右)地近似上面迭代法的计算结果,从而在提高性能的同时,保证模拟的结果。
(这篇文章主要是针对二维流体模拟的情况,在今年的Siggraph 2022上,他们也发布了针对三维流体模拟的论文)
Compact Poisson Filters for Fast Fluid Simulation, SIGGRAPH 2022 下面我尝试解释一下[2]的思路和流程,最后给出一些实现细节和测试结果。
<hr/>对于计算压力时的迭代式, p^{k+1}_{i,j}=\frac{p^{k}_{i+i,j}+p^{k}_{i-1,j}+p^{k}_{i,j+1}+p^{k}_{i,j-1}-l^2*div_{i,j}}{4} ,从初值 p^{0}_{i,j}=0 开始迭代。
p^{1}_{i,j}=\frac{p^{0}_{i+i,j}+p^{0}_{i-1,j}+p^{0}_{i,j+1}+p^{0}_{i,j-1}-l^2*div_{i,j}}{4}=\frac{-l^2div_{i,j}}{4}
p^{2}_{i,j}=\frac{-l^2div_{i+1,j}}{16}+\frac{-l^2div_{i-1,j}}{16}+\frac{-l^2div_{i,j+1}}{16}+\frac{-l^2div_{i,j-1}}{16}+\frac{-l^2div_{i,j}}{4}
......
如此展开下去,可以看到压力递推公式的结果,可以表示为当前位置以及附近位置速度的散度的加权平均。
这样的加权平均的操作也就是图像处理领域中的卷积操作。
例如我们展开迭代两次和三次的递推式,当前位置的压力结果,与附近散度的权重关系如下图所示,这个权重关系与图中的卷积核(卷积矩阵)是对应的。
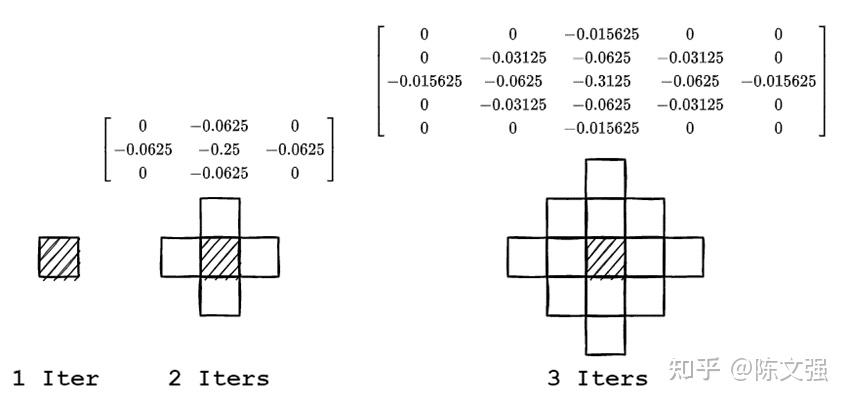
如果给定一个迭代次数,可以离线展开递推公式,得到最终迭代结果与周围散度的权重关系。
在运行时,就可以不进行迭代计算,直接根据展开递推式得到的卷积核矩阵,对速度的散度场进行一次卷积就可以得到对应的压力场了。
以迭代次数为3为例验证这个思路是否可行。
我们之前已经计算出卷积核,那我们通过一个简单的卷积Shader替换掉Volumetric插件中的迭代操作,也就是用卷积(One Pass)替换迭代三次(Three Passes)求解压力场。
const float Kernel0[5] = {0.0, 0.0, -0.015625, 0.0, 0.0};
const float Kernel1[5] = {0.0, -0.03125, -0.0625, -0.03125, 0.0};
const float Kernel2[5] = {-0.015625, -0.0625, -0.3125, -0.0625, -0.015625};
const float Kernel3[5] = {0.0, -0.03125, -0.0625, -0.03125, 0.0};
const float Kernel4[5] = {0.0, 0.0, -0.015625, 0.0, 0.0};
float2 UVPerPixel = float2(1.0, 1.0) / Resolution.xy;
float2 Direction = float2(UVPerPixel.x, 0.0);
float WeightedAverage = 0.0f;
float2 UVOffset0 = float2(UV.x - 2 * UVPerPixel.x, UV.y - 2 * UVPerPixel.y);
for (uint Index = 0; Index < 5; Index++)
{
float2 SampleUV = UVOffset0 + Direction * Index;
WeightedAverage += InputTexture.SampleLevel(InputTextureSampler, SampleUV, 0).r * Kernel0[Index];
}
// Omit other 4 rows.
下面两个视频是修改前后的效果对比,可以看到效果是差异不大的。

迭代法 | 迭代次数 3
https://www.zhihu.com/video/1553009996450979840

卷积核 | 迭代次数 3
https://www.zhihu.com/video/1553010429630394368
这样修改后,我们只需要一个Pass,就可以完成之前需要三个Pass的操作,减少了RT的切换。
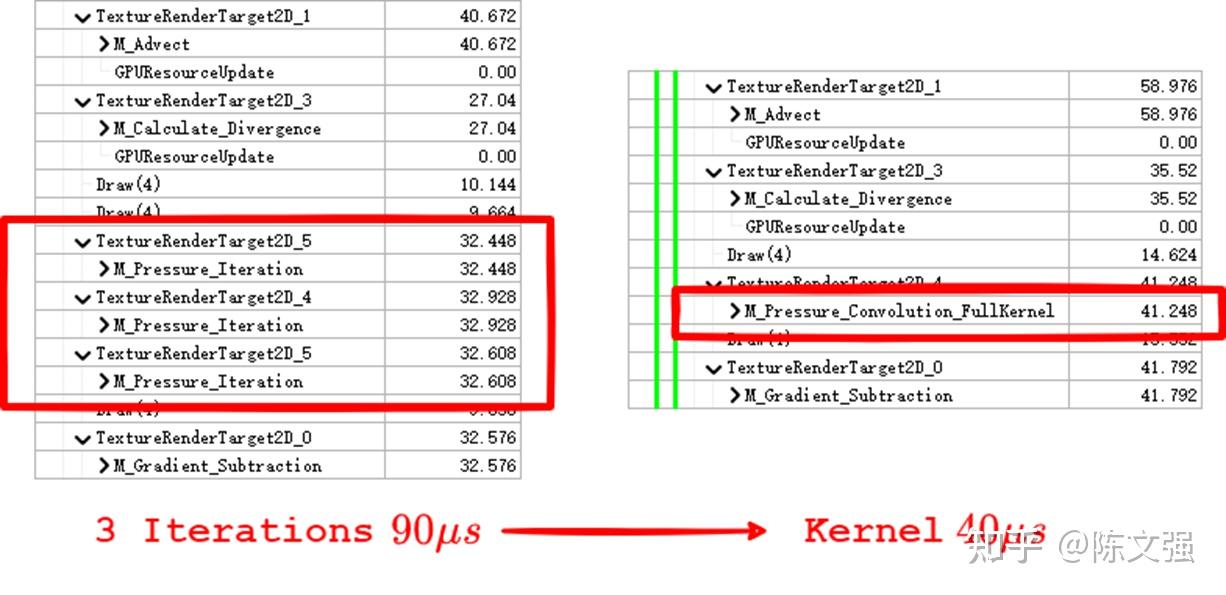
那这种“毕其功于一役”的方案,是不是一种实际可行,可落地的方案?
如下图所示,随着迭代次数的增加,用递推式展开得到的卷积核的大小也在迅速增加。
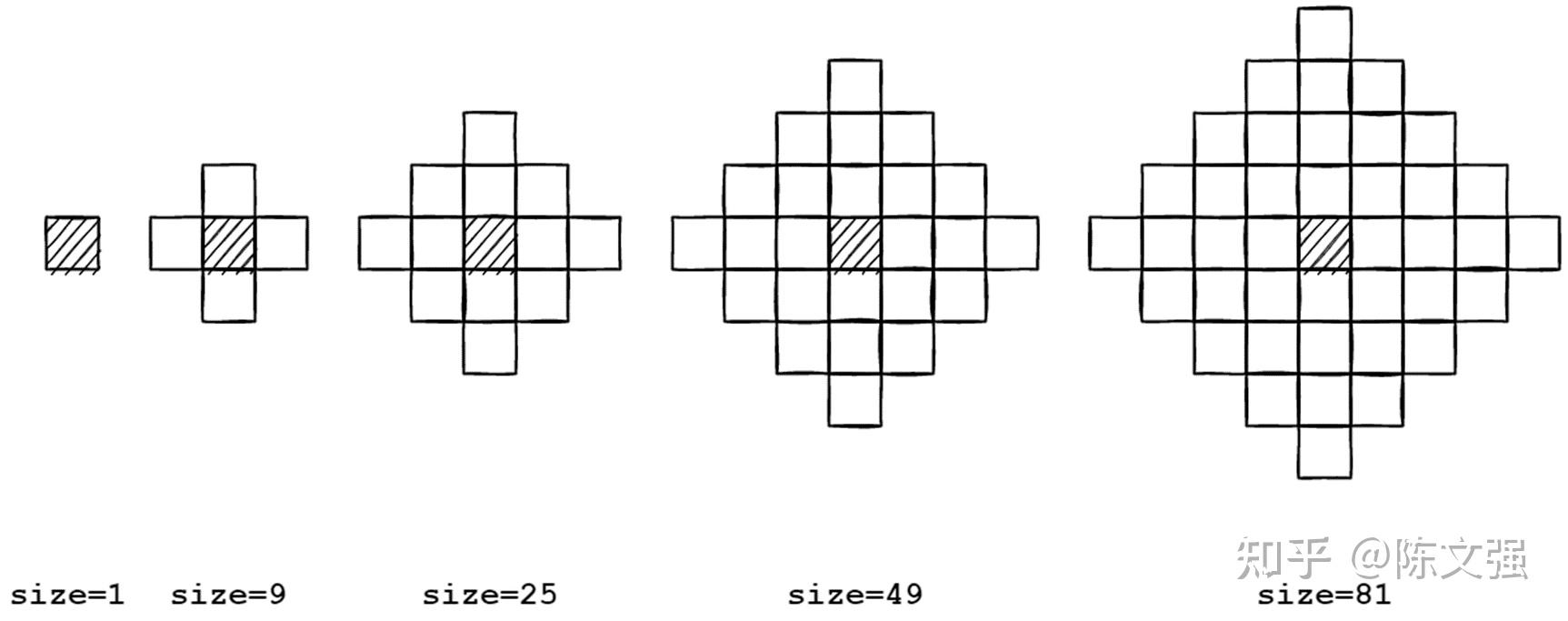
也就意味着,每个像素在完成一次卷积操作时,需要采样的次数也在迅速增加。
通过简单推导可知:
KernelSize(n)=(2n-1)^2
也就是说
当 n=30,N_{sample}\approx3600 ,每个像素在卷积时,需要采样三千六百多次,这在实时应用中是无法接受的。
实际上,通过观察卷积矩阵,可以发现矩阵中蕴含的信息是非常冗余的。
例如,整个矩阵是中心对称的,四周也有大量的零元素,我们可以通过提取矩阵的特征信息,用更紧凑的数据来近似表达整个矩阵。
[2] 中使用的是矩阵的奇异值分解(SVD)来完成卷积矩阵的压缩。
这里利用了SVD中的一个重要性质:经过SVD得到的矩阵的奇异值,如果把所有奇异值排序,并累加,前5%奇异值的和能够占到所有奇异值之和的90%以上。
以下面的图示为例,我们对原矩阵进行SVD,然后改写成奇异值与其对应左右奇异向量相乘的和的形式之后,按照上面的性质,最大的奇异值跟它的左右奇异向量相乘之后的矩阵,对原矩阵能有非常不错的近似(红圈圈出部分)。
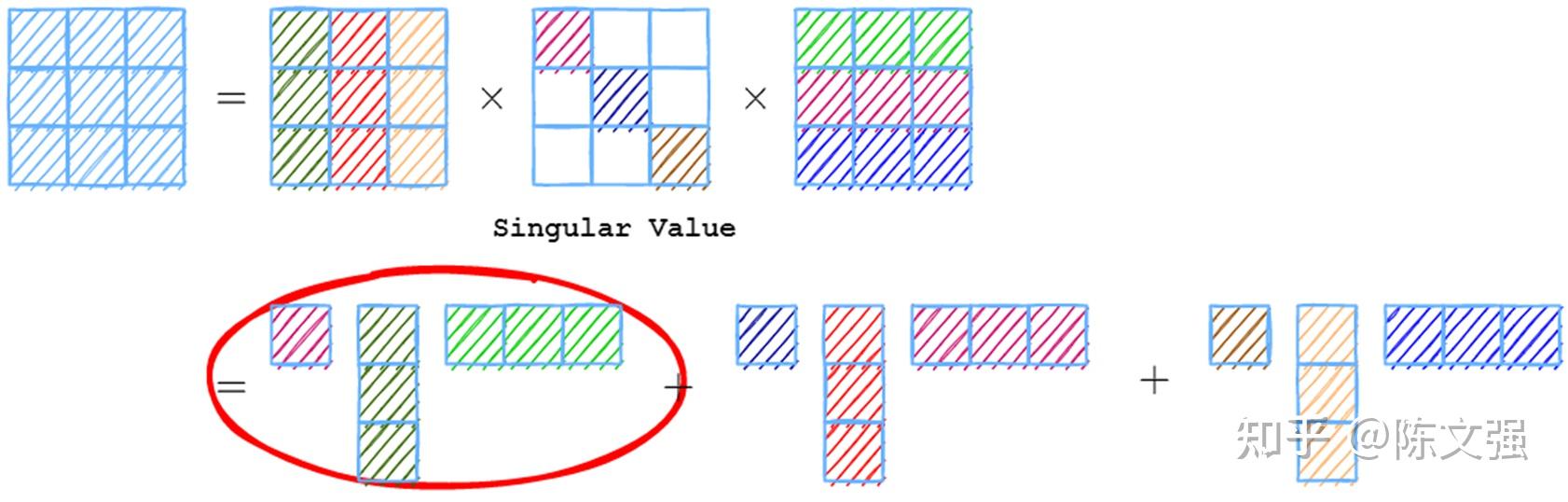
同时,可以看到分解得到的矩阵是由一个行向量和列向量相乘(外积)得到的,也就是说这个分解得到的“秩1矩阵”能够很好地近似原本的卷积核矩阵。
那么我们就可以用生成这个“秩1矩阵”的列向量和行向量作为滤波核,对存储散度场的纹理实施垂直和水平两个方向的可分离滤波(Separable Filtering),达到一个对原本使用卷积矩阵进行卷积操作的近似。
这样采样的数量就从卷积的 O(n^2) 降到 O(n) 。
总结一下:
与迭代法相比,RT的切换(需要的Render Pass)更少,只需要固定的两个方向的可分离滤波。
与直接使用卷积核进行卷积相比,采样数更少。
<hr/>3. 实现
想要实现上面的流程,第一步是需要根据给定的迭代次数,计算出相应的卷积核,然后对卷积矩阵进行SVD得到滤波核。
作为一名合格的“Python Boy”,我是写了个简单的Python脚本完成这部分计算,没有用到Matlab等高大上的工具。
CacheDict = {}
def DivergenceIter(I, J, K):
CachedValue = CacheDict.get((I, J, K))
if CachedValue is not None:
return CachedValue
KernelSize = 2 * IterationCount - 1
Kernel = numpy.zeros((KernelSize, KernelSize))
if K == 0:
return Kernel
else:
XIMinus1J = DivergenceIter(I - 1, J, K - 1)
XIPlus1J = DivergenceIter(I + 1, J, K - 1)
XIJMinus1 = DivergenceIter(I, J - 1, K - 1)
XIJPlus1 = DivergenceIter(I, J + 1, K - 1)
Kernel[I][J] = 1
Ret = XIMinus1J * 0.25 + XIPlus1J * 0.25 + XIJMinus1 * 0.25 + XIJPlus1 * 0.25 - Kernel * 0.25
CacheDict[(I, J, K)] = Ret
return Ret
def DivergenceKenel(IterationCount):
KernelSize = 2 * IterationCount - 1
CenterIndex = KernelSize // 2
Kernel = DivergenceIter(CenterIndex, CenterIndex, IterationCount)
return Kernel
def Svd(Kernel):
U, Sigma, VT = numpy.linalg.svd(Kernel)有了这个离线计算滤波核的工具脚本后,还是以之前迭代次数为3的简单情况验证下脚本是否正确。
当迭代次数为3时,卷积核以及通过SVD得到的滤波核如下图所示。
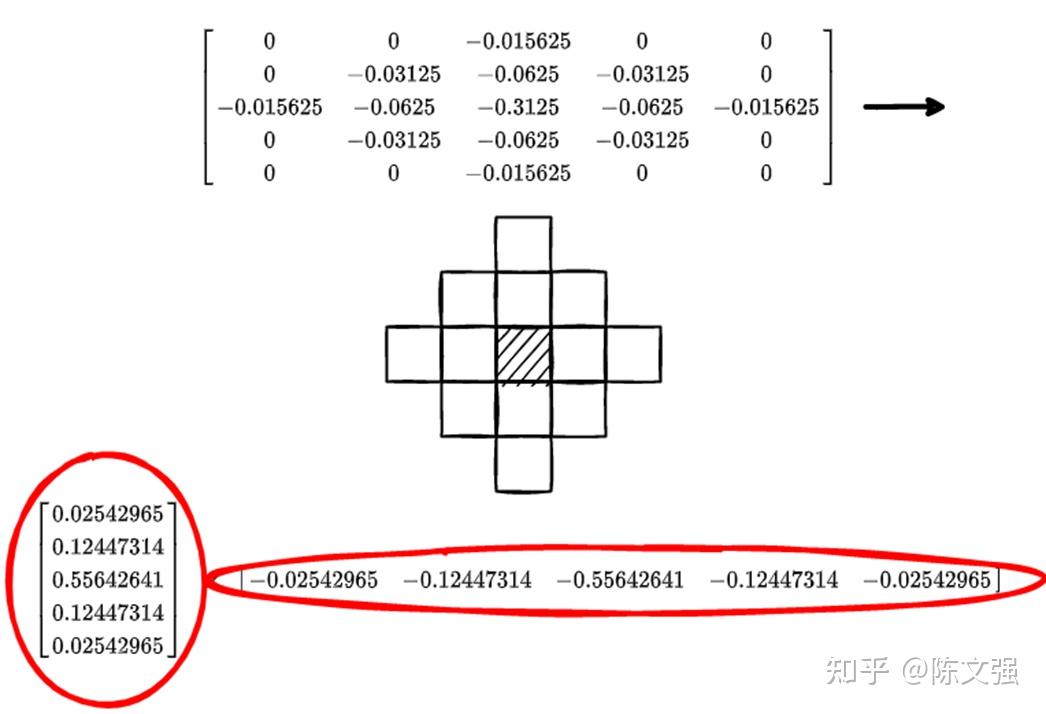
可以看到两个方向上的滤波核数值的绝对值是相等的,只有符号的差别。
然后对Volumetric的二维流体模拟从迭代法改为使用滤波的方式,可以得到如下的结果

可分离滤波 | 迭代次数 3
https://www.zhihu.com/video/1553363098110697473
与先前使用迭代法,卷积核卷积的效果对比,效果上的差异是能够接受的。
在实际使用中,我使用的迭代次数是32次,计算得到的滤波核如下所示(因为两个方向的滤波核只有符号的差异,权重的绝对值是相同的,因此只给出垂直方向),根据先前的公式可知,当迭代次数是32时,滤波核的大小为63。
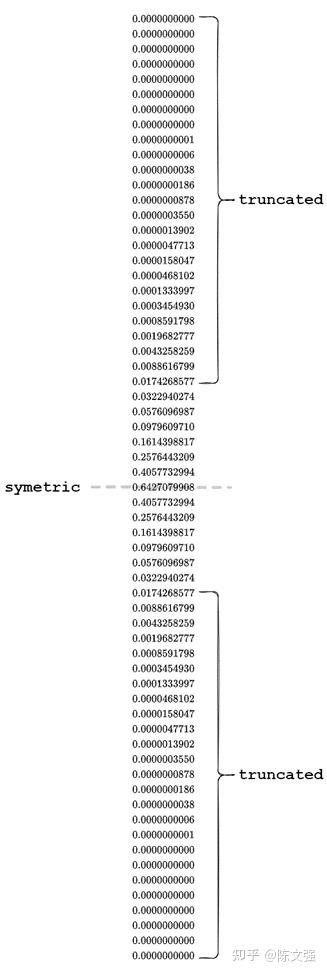
通过观察滤波核发现,滤波核中的数值也是中心对称的,并且滤波核中两侧的权重衰减得也很快。
在实际进行滤波的时候,这些低权重的值对最终结果的影响很小,所以还可以进一步对滤波核进行瘦身,只保留中间权重较高的部分。

裁剪后的滤波核
把这个滤波核抄到Custom Node里面,完成滤波的计算。
const float Kernel[13] = {0.0322940274, 0.0576096987, 0.0979609710, 0.1614398817, 0.2576443209, 0.4057732994, 0.6427079908,
0.4057732994, 0.2576443209, 0.1614398817, 0.0979609710, 0.0576096987, 0.0322940274};
float2 UVPerPixel = float2(1.0, 1.0) / Resolution.xy;
float2 Direction = float2(0.0f, UVPerPixel.y);
float2 OffsetCenterUV = float2(UV.x, UV.y - ((UVPerPixel.y * (13 - 1)) / 2.0f));
float WeightedAverage = 0.0f;
for (uint Index = 0; Index < 13; Index++)
{
float2 SampleUV = OffsetCenterUV + Direction * Index;
WeightedAverage += InputTexture.SampleLevel(InputTextureSampler, SampleUV, 0).r * Kernel[Index] * -1.0f;
}
return WeightedAverage;流程调整为使用预计算滤波核计算压力场的二维流体模拟的效果

可分离滤波 | 迭代次数 32
https://www.zhihu.com/video/1553367917449641984
与先前使用迭代法迭代32次时的效果对比,可见效果上的差异依然是可以接受的。当然更重要的是,此时模拟系统的效率能有很大的提升。
以下是桌面端的对比测试:

桌面端对比
在移动端的对比测试:
测试环境,iPhone11,模拟分辨率 512 x 512
可见,在修改后,整个模拟的流程在移动端可以压缩到1ms以内。
并且512 x 512的分辨率,在很多应用场景下是不需要这个精度的,所以还可以适当调整模拟的精度,进一步减少模拟部分的消耗。
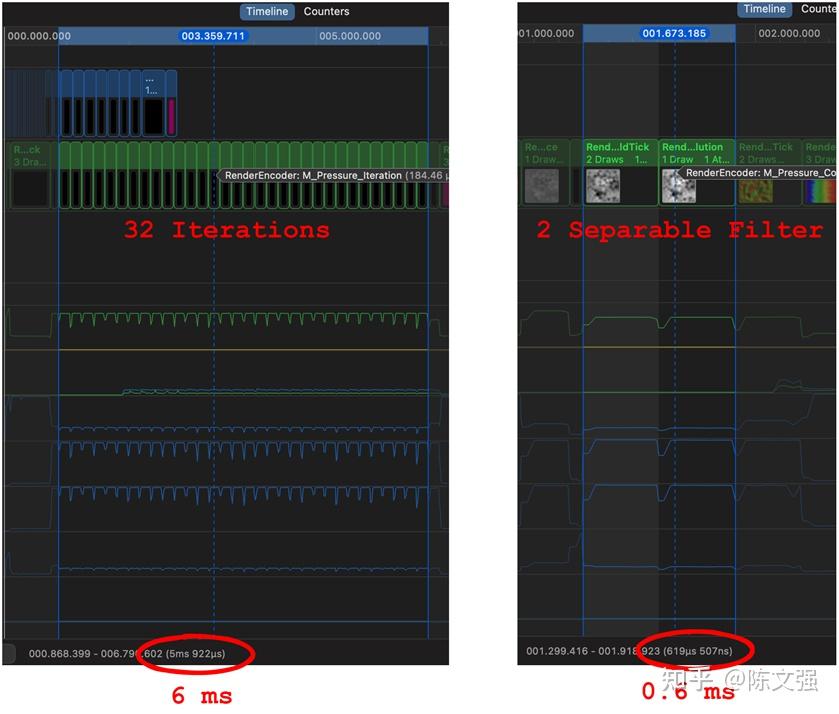
移动端对比
<hr/>4. 小结
后来我发现,在一些UE4的插件中也有类似的做法。
例如FluidNinjaLive这个插件中,他们也是通过类似的可分离滤波完成对压力场的求解,不过跟他们交流过后,他们表示他们的滤波核是通过“实验数据”得来的,因此上文算是对这种“实验数据”的一种理论补充。
另外FluidNinjaLive中,使用的是两个滤波核分别对原本的压力场与散度场进行滤波,这可以对应为展开迭代式时的初始条件不同。
[2] 是以初值为0开始展开的,而FluidNinjaLive中,如果以上一帧的压力场作为初值展开的话(亦被称为Warm Start),就能得到上一帧压力场和散度场两个滤波核了。
<hr/>在最后写点废话,其实文章的主体部分是早前住院期间写的,(实在是太无聊了啊(;´༎ຶД༎ຶ`),疫情期间住院不能外出也不能探视,不然也不会有闲情雅致写这么多字),还是希望大家能够身体健康,身体好才是硬道理(尤其是那些能读到这里的朋友(๑ ꒪ꌂ꒪๑))。加油嘞~(ᕑᗢᓫ∗)˒。 |
|



 发表于 2022-9-22 17:45:26
发表于 2022-9-22 17:45:26