|
|
从H100的的架构白皮书中我们可以看到[1],H100 TensorCore的算力是A100的3倍,包括了提频和SM数量增加的收益。单个SM的TensorCore在同频率下是A100的2倍。看起来是一个比较普通的提升,然而底层指令上的变化却非常大。
WMMA:Volta~Ampere
从Volta推出TensorCore开始,TensorCore的指令就被叫做xMMA指令(SASS)或WMMA指令(PTX[2]),例子:
HMMA.xxx Rd, Ra, Rb, Rc;A/B/C/D四个矩阵分布在一个warp的32个线程的register中。这可能会带来一些问题:
- 对于register占用量大
- 对于register读写端口压力大,为了性能,必须用好register reuse cache
- 所有操作数都是寄存器,需要频繁的从shared memory和global memory读数据。为了缓解这个问题,A100已经增加了async_copy(LDGSTS)功能,从GM直接拷贝数据到shared memory
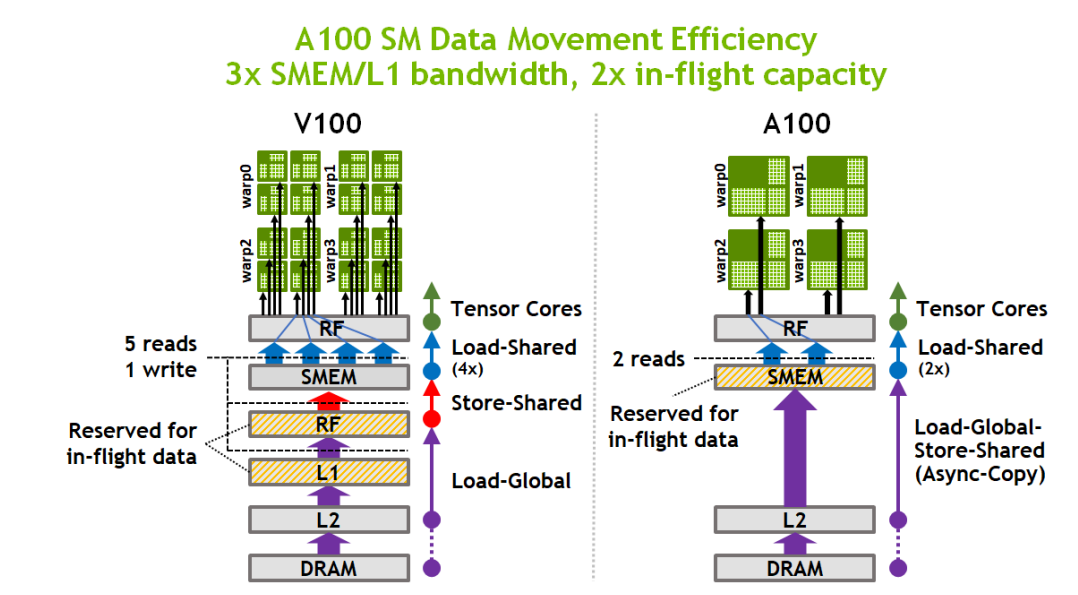
A100相对于V100,数据相当于少走一次回头路
WGMMA:Hopper Only?
目前CUDA12已经发布,PTX中发布了WGMMA指令[3],同时在cuobjdump的Hopper指令集文档[4]中也可以看到相关指令。不过暂时还没有公开的云服务提供H100的机器。
兼容性问题
GTCFall上NV明确说明Hopper下一代不兼容WGMMA,要PTX代码兼容就不要用WGMMA,改用WMMA。同时在Hopper上只有WGMMA才能达到最高的性能。为此还专门搞了个sm_90和sm_90a两个版本号
Warp Group
4个连续的warp可以组成一个warp group,也就是说thread [0,127]是一个warp group, 这正好对应着SM Core的4个分块(应该叫processing block来着?)和4个TensorCore。
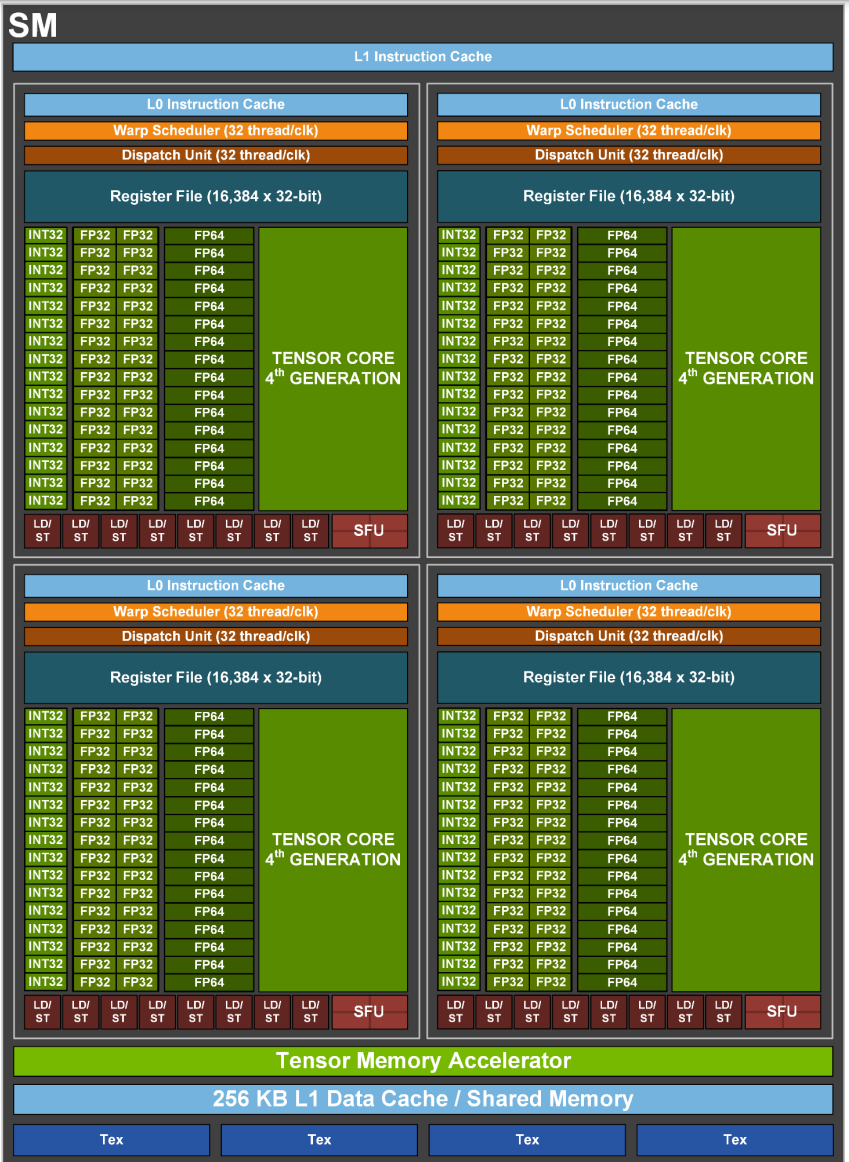
Warp Group MMA
PTX中有4条WGMMA相关的指令:
- wgmma.mma_async
- wgmma.fence
- wgmma.commit_group
- wgmma.wait_group
wgmma.mma_async是TensorCore的计算指令。它有几个特点:
- 这是一条异步的指令,执行时间是不确定的(因为要读shared memory)
- A矩阵可以是Register或shared memory,B矩阵必须从shared memory直接读取
- 矩阵乘法(fp16)的M=64和K=16是固定的,但是N是可变的: 8~256, 要求是8的倍数。N要求是个常数,不能运行时修改(实际应该是设置在指令的encoding中)。
wgmma.fence指令的作用是保证在fence之前的mma指令执行完成之后再发射fence之后的mma指令,保证register数据依赖的正确性(比如多条mma指令在K方向上累加的场景)
wgmma.commit_group指令: 将之前发射的mma指令打包成一个group提交。
wgmma.wait_group指令: 使得执行wait group指令的线程等到还有N个group没有完成,N=0的话就是等待所有mma group完成,这里的N也是一个常数。
从上面4条指令可以看出,Hopper的TensorCore与之前的TensorCore有比较大的区别,更加的像一个异步的加速器,有一个TensorCore专用的queue(有点像TPU和NPU),单条指令执行的计算量更大(64x256x16), CUDA线程需要向TensorCore提交任务,然后可以完成一些别的工作,最后通过同步指令等待结果。
以上是WGMMA对应PTX的指令和编程模型,然而实际上SASS中的实现并不一样,后续我会从一些SASS的反汇编代码分析一下实际的机器指令实现。
参考
- ^GTC22 Hopper白皮书 https://resources.nvidia.com/en-us-tensor-core
- ^WMMA ptx指令 https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-instructions
- ^WGMMA ptx指令 https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#asynchronous-warpgroup-level-matrix-instructions
- ^warp group instructions https://docs.nvidia.com/cuda/cuda-binary-utilities/#hopper-instruction-set
|
|



 发表于 2023-2-7 16:43:13
发表于 2023-2-7 16:43:13