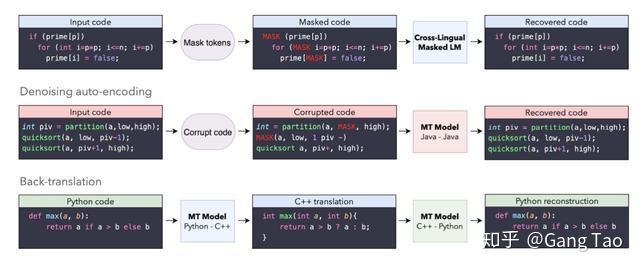
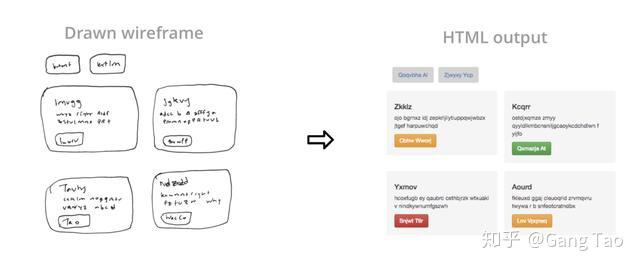
详情可以参考 https://ai.facebook.com/blog/aroma-ml-for-code-recommendation/ CodeBERT
微软、哈工大在arxiv上联合发表了一篇论文,标题为《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》,再次拓宽了BERT的应用,将BERT应用到了Python、PHP、Java、JavaScript、Go、Ruby等编程语言的代码搜索和生成任务当中。整体方案仍然是传统的预训练+微调框架,模型规模不大。
BERT作为一种双向Transformer的编码器,其对预训练方法的创新深受业界和学术界的喜爱,虽然其他大规模的预训练模型例如ELMo、GPT等已经能够在各种NLP任务中提升SOTA。
但是上述提到的模型基本上都是面向自然语言处理,例如掩蔽语言建模、从未标记文本学习上下文表示。 相比以往的Bert的应用场景,作者另辟蹊径,推出双模态预训练模型,即兼顾NLP任务和Python、Java等编程语言。
具体来说,CodeBERT抓住了自然语言和编程语言之间的语义联系,能够支持自然语言代码搜索等NL-PL理解任务以及一系列像代码生成这样的生成任务。
整体方案:预训练语言模型+下游任务微调
预训练语言模型:结合NL-PL双模态Masked Language Modeling和PL单模态Replaced Token Detection训练目标的1.25亿参数预训练模型;训练损失函数为min(LMLM+LRTD)。



 发表于 2022-12-13 00:28:07
发表于 2022-12-13 00:28:07